
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций

Как правило, в системе хранения данных (СХД) размещается несколько версий одной и той же информации, которые наследуются по мере развития информационного проекта или информационной системы. Дедупликация помогает снизить стоимость владения СХД, так как подразумевает использование меньшего количества дисковых ресурсов для хранения одного набора данных по сравнению с исходным.
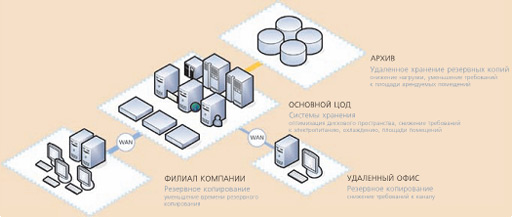
Еще более значителен выигрыш этой технологии в контексте систем резервного копирования. Не секрет, что обработка и хранение больших объемов повторяющихся данных приводит к дополнительным затратам на дисковое или ленточное пространство, потребляемую электроэнергию (электропитание и охлаждение приводов), а также на обеспечение требуемой пропускной способности сетей передачи и хранения данных. За счет меньшего объема данных, требуемых для передачи между серверами и клиентами систем резервного копирования, дедупликация сокращает время операций резервного копирования и восстановления.
Варианты реализации систем дедупликации различны и во многом зависят от производителя соответствующего программного или аппаратного обеспечения. Ряд вендоров предоставляет программную реализацию дедупликации, включая серверное и клиентское ПО. Другие предлагают аппаратные решения, имитирующие файл-сервер для сетей передачи данных или виртуальную ленточную библиотеку для сетей хранения данных.
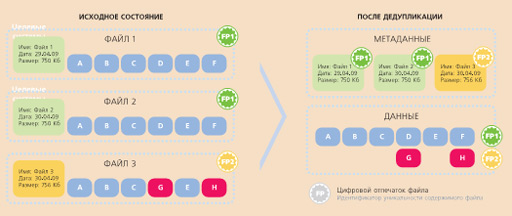
Реализация технологии в обоих случаях такова: алгоритм дедупликации на источнике или получателе информации в зависимости от реализации сегментирует входящий поток данных, уникально идентифицирует полученные сегменты, а затем сравнивает с обработанными ранее. Если новый сегмент является копией ранее сохраненного, то он не размещается на системе хранения, а вместо него записывается ссылка на ранее сохраненный. Если же входящий сегмент уникален, то он помещается на конечное устройство хранения.
Например, регулярное резервное копирование одного файла или дискового
тома с использованием обычных политик резервирования приводит к хранению нескольких одинаковых копий. В случае использования дедупликации соответствующий алгоритм позволяет проанализировать записываемые данные и поместить на систему хранения только измененные части файла или тома. Таким образом можно сократить в десятки и даже в сотни раз требования к объему ресурсов, необходимых для хранения резервных копий. И для резервирования 20 терабайт данных может потребоваться выделение под резервные копии всего лишь 1 терабайта.
Наиболее значимые для степени дедупликации параметры – это уровень изменения данных (чем меньше изменений, тем больше данных дедуплицируется), частота создания резервных копий (чем больше полных резервов, тем больше уровень дедупликации), период хранения копии (длительные периоды приводят к большему объему данных для сравнения) и размер пакета данных (чем больше данных, тем больше дедупликация).
Существуют два метода обработки данных при дедупликации. Поточный, inline-метод, предполагает дедупликацию данных перед их записью на ресурсы хранения. Метод post-process проводит анализ и обработку данных после их размещения на ресурсах хранения. Наиболее эффективным и экономичным методом является inline-дедупликация, так как именно этот способ позволяет значительно снизить требования к ресурсам хранения, поскольку входящие недедуплицированные данные не записываются на диск. Post-process-метод предполагает схему, при которой данные сначала записываются на диск, после чего запускается процесс их дедупликации. А это требует изначально больших дисковых ресурсов и больше временных затрат для всего процесса.
Дедуплицировать блоки данных можно также двумя способами. Первый подразумевает независимость от типа исходных данных, генерируемых различными приложениями. Преимущество его в том, что для системы дедупликации не важен формат исходных данных, используется анализ сегментированных входных raw-данных. Второй основывается на использовании информации о формате и способах хранения данных внутри исходного набора данных, например форматов файлов, генерируемых распространенными приложениями. При дедупликации производится разбор формата поступающих данных, определяются изменения, внесенные в исходный набор данных. И только эти изменения помещаются на ресурсы хранения. Данный подход существенно улучшает степень компрессии, однако не может служить эффективным универсальным методом для процесса дедупликации в целом.
При использовании дедупликации в аппаратных решениях следует учитывать ее влияние на производительность СХД. Так, первичные системы хранения данных используются для основного размещения данных ЦОД и ориентированы на оптимальную производительность при осуществлении операций ввода-вывода данных. Поэтому выполнение их дополнительной обработки может негативно повлиять на скоростные характеристики дискового массива. Вторичные системы хранения обеспечивают защиту данных первичных СХД путем размещения логической копии основных данных. Данные системы, как правило, не используются при поточной обработке производственных данных. Применение таких СХД для дополнительных операций с данными не влияет негативно на показатели производительности основных систем и в то же время позволяет повысить эффективность размещения информации в ЦОД. Вот почему в настоящее время технологии дедупликации данных применяются, как привило, во вторичных СХД. Тем не менее в первичных системах хранения данных также может использоваться эта технология, если затраты ресурсов СХД на данный процесс несущественны или влияние на производительность незначительно.
Среди явных преимуществ дедупликации можно назвать:
Приведем некоторые примеры реализации технологий дедупликации ведущими производителями.
Компанией EMC реализованы технологии дедупликации в решениях Data Domain и Avamar. Дисковые системы EMC Data Domain представляют собой специализированные устройства, обеспечивающие хранение резервных копий, дедупликацию, репликацию и позволяющие эмулировать как ленточные библиотеки, так и файловые серверы (протоколы CIFS, NFS и OST). В этих системах используется алгоритм дедупликации на уровне блоков данных переменной длины. Поддерживается inline-дедупликация. Решение EMC Avamar аппаратно строится на базе х86-серверов и представляет собой grid-кластер, реализующий так называемую RAIN-архитектуру
(Redundant Array of Independent Nodes – избыточный массив независимых узлов), что позволяет повысить надежность и масштабируемость комплекса (метаинформация хранится совместно с дедуплицированными данными). Программное обеспечение реализует технологию глобальной дедупликации на источнике данных, используются сегменты переменной длины.
Компания NetApp позволяет использовать дедупликацию как для первичных систем хранения данных FAS (системный уровень Data ONTAP/WAFL), так и для массивов класса VTL. Для первичных СХД используются post-process-дедуплика-ция (таким образом нивелируется влияние процесса дедупликации на производительность массива в рабочие часы) и блоки постоянной длины. Для VTL-класса, помимо post-process, также могут применяться inline-дедупликация и сегменты переменной длины.
Компания Symantec использует технологии дедупликации в программном обеспечении резервного копирования и восстановления NetBackup и Backup Exec. Опции дедупликации NetBackup, основанные на решении PureDisk, дают возможность проводить дедупликацию как на стороне источника данных с помощью клиентского программного обеспечения, так и на целевом устройстве c помощью медиасервера резервного копирования. Есть также возможности применения внешней дедупликации посредством интеграции c устройствами OpenStorage и копирования дедуплицированнных данных из филиалов компании в основной ЦОД. Дедупликация работает как на файловом, так и на уровне блоков данных. Возможно использование inline-метода. Дедупликация в Backup Exec основана на технологиях, аналогичных применяемым в NetBackup.
Компания Oracle предоставляет возможности дедупликации на уровне файловой системы Solaris ZFS. Дедупликация производится на уровне блоков.
Завершая рассказ о технологии деду-пликации, стоит отметить, что, по оценкам аналитической компании Gartner, внедрение систем с дедупликацией быстро прогрессирует и к 2012 г. ожидается, что дедупликация будет использоваться по крайней мере в 75% систем, обеспечивающих инфраструктуру резервного копирования.
Опубликовано: Журнал "Технологии и средства связи" #5, 2010
Посещений: 12028
Автор
| |||
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
