
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций

Развитие современных технологий позволяет использовать сложные биометрические алгоритмы распознавания для аутентификации личности и предоставления прав доступа к устройствам и приложениям. Биометрические алгоритмы распознавания применяются для технологии сканирования отпечатков пальцев, радужной оболочки или сетчатки глаза, геометрии рук; для распознавания по лицу; для распознавания речи. Преимуществом технологии распознавания речи является отсутствие дополнительного сканирующего оборудования. Для систем, работающих в реальном масштабе времени, необходимо только наличие микрофона для анализа речи. Технология отличается невысокой стоимостью реализации, при этом может быть использована на встраиваемых устройствах.
Речь является одной из форм представления языка и содержит большое количество информации о своем источнике. Она позволяет определить пол человека, судить о его здоровье и эмоциональном состоянии. Речь необходима для общения, т.е. коммуникации между объектами (людьми или системами обработки речи), в процессе которой происходит обмен информацией. Речь можно описать как ее информационным содержанием, так и в виде сигнала, т.е. акустического колебания. Обработку такого вида сигналов рассматривает теория цифровой обработки речевых сигналов [1]. Теория подразделяет все системы речевого обмена между человеком и машиной (в случае IoT в качестве машины выступает объект пространства Интернета вещей) на три класса: с речевым ответом, распознаванием диктора и распознаванием речи. Более подробно рассмотрим системы второго класса, которые, в свою очередь, распадаются на два подкласса: системы верификации и идентификации диктора.
Верификация речи – процесс решения задачи о принадлежности диктора к некоторой группе лиц. В процессе верификации диктору требуется ввести в систему свои данные, подтверждающие его право на аутентификацию, а затем произнести эталонную фразу. Система обработает произнесенную фразу для определения характеристик речевого сигнала, сравнит их с характеристиками эталона, данные которого были указаны диктором, построит матрицу потерь cl (1), определяющую полную ошибку, и вынесет решение об идентичности диктора заявленному лицу. При верификации необходимо однократное сравнение измеренных значений со значениями эталона, на основе которого и принимается решение об идентичности диктора. Решение об удачной верификации принимается на основе правила вида:
Верифицировать диктора l, если

Отклонить диктора l, если
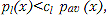
где cl– константа для l-го диктора, определяющая вероятности ошибок l-го диктора, pω (x) – среднее распределение вероятности (по всему набору дикторов) измеренных значений вектора x. Изменяя порогcl, можно изменить вероятность ошибки, определяемую вероятностями ложной верификации или отказа верификации подлинного диктора.
Идентификация речи – это выделение диктора из некоторого известного множества. Ее задача состоит в том, чтобы точно указать одного из дикторов среди N дикторов множества. Поэтому в отличие от верификации вместо однократного сравнения измеренных параметров с хранящимися параметрами в виде эталона необходимо провести N сравнений. Правило принятия решения в этом случае сводится к выбору такого диктора l, для которого
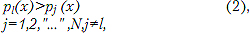
т.е. определяется диктор с минимальной абсолютной вероятностью ошибки. При этом с увеличением количества дикторов во множестве возрастает и вероятность ошибки, т.к. большое число вероятностных распределений в ограниченном пространстве параметров не может не пересекаться. Более вероятным становится тот факт, что два или более дикторов в общем множестве будут иметь распределение вероятностей близким друг к другу. Все это негативно влияет на качество принятия решения при идентификации диктора.
Задачи верификации и идентификации речи являются по своей сути сходными, но в то же время присутствуют и различия. В каждом случае диктор должен произнести тестовую фразу. В процессе анализа фразы производятся измерения, а затем вычисляются одна или несколько мер различимости между текущими и эталонными параметрами. На этом шаге с позиции цифровой обработки обе задачи сходны. Основное же различие между ними возникает на этапе вынесения решений, где в случае верификации требуется выполнить задачу бинарного выбора, т.е. принять или отклонить утверждение, что голос верифицируемого диктора идентичен эталону. Для этого достаточно использование нормированной суммы квадратов
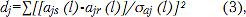
где ajs (l) – значение j-й траектории входного сигнала в момент l; ajr (l) – значение j-й траектории эталона в момент l; σaj (l)– стандартное отклонение j-й траектории в момент l. Полная же мера различимости может представлять собой взвешенную сумму корней

где ωj – вес, выбираемый на основе значимости j-го измеренного значения траектории верифицируемого сигнала.
В случае идентификации речи вычисление (4) недостаточно, и необходимо использование более сложных мер различимости, основанных на вероятностных моделях. Классическими примерами таких моделей являются скрытая марковская модель (СММ/HMM) и модель смеси нормальных гауссовых распределений (СГР/GMM). СММ – это статистический метод, предполагающий, что модель системы есть марковский процесс с неизвестными параметрами. Целью метода является определение неизвестных параметров цепи на основе наблюдаемых. СГР является параметрической функцией плотности вероятности, представленной как взвешенная сумма функций нормального распределения (гауссовских компонент). Нейронные сети и метод опорных векторов (SVM) также нашли свое применение в сфере идентификации речи, но активная исследовательская деятельность в этой области еще продолжается.
Согласно исследованию [2] для текстонезависимых систем модели СГР более эффективны по сравнению со СММ, показывающим лучший результат для систем, где произносимый диктором текст известен заранее. Поэтому для разработки системы верификации/идентификации диктора имеет смысл использование именно модели СГР. В качестве примера такой работающей системы можно привести проект ALIZE [3]. ALIZE представляет собой открытую платформу биометрической аутентификации, разработанную на языке Си и используемую для идентификации и верификации речи. Платформа содержит все необходимые функции для обработки речи и работы с моделью СГР.
В общем виде процесс идентификации на основе модели СГР можно описать последовательностью следующих шагов:
1. Извлечение из речевого сигнала индивидуальных особенностей голоса человека (признаков). На этом шаге фрагменты речи преобразуются в параметры вектора, а весь речевой сигнал представляется последовательностью этих векторов.
2. Создание универсальной фоновой модели (УФМ/UBM). УФМ описывает усредненные голосовые характеристики всех дикторов известного множества. В дальнейшем на основании этой модели вычисляется степень уникальности речевого сигнала, которая используется для вынесения решения об идентификации диктора или его отклонении. УФМ создается на этапе обучения системы.
3. Создание модели СГР (голосовой модели) для каждого диктора во множестве. На этом шаге обрабатывается УФМ в сочетании с последовательностью векторов голосовых признаков каждого диктора из множества с использованием метода апостериорного максимума (MAP) [4]. Голосовые модели создаются на этапе обучения системы.
4. Оценка полученных после обработки входного речевого сигнала признаков относительно голосовой модели каждого диктора во множестве.
5. Принятие решения об идентификации диктора в зависимости от установленного в системе порога и на основании оценки каждой голосовой модели.
Следует отметить, что системы верификации/идентификации диктора работают в двух режимах. Первый режим – обучения, или режим создания эталонных моделей, когда на основе набора звуковых записей дикторов (wav, raw и т.д.) создается УФМ, а затем голосовая модель каждого диктора (шаги 1–2–3). Второй режим – рабочий, когда из верифицируемого/идентифицируемого речевого сигнала выделяются признаки, а затем на основании этих признаков производится поиск голосовой модели в наборе эталонов (или сравнение с указанной голосовой моделью в случае верификации) и принимается решение о верификации/ идентификации диктора или его отклонении (шаги 1–4–5).
Для создания модели системы верификации/идентификации диктора на встраиваемом устройстве был выбран, как отмечалось ранее, открытый проект ALIZE. В качестве встраиваемого устройства использовался одноплатный компьютер с 4-ядерным процессором ARM Cortex-A7 900 МГц и 1 Гбайт ОЗУ, на котором было установлено необходимое для сборки Си-кода программное обеспечение. Платформа ALIZE версии 3.0, состоящая из низкоуровневой библиотеки ALIZE и набора инструментальных программ LIA_RAL, была сконфигурирована и собрана непосредственно на встраиваемом устройстве. Признаки речи извлекались с помощью программного инструмента обработки речи SPro [5] версии 4.0.1. Для обучения и тестирования системы использовались фрагменты речи актеров из различных кинофильмов. По мнению автора, полученные таким образом эталонные голосовые модели наиболее подобны моделям, созданным в реальных, а не студийных условиях, и содержат различные естественные шумы.
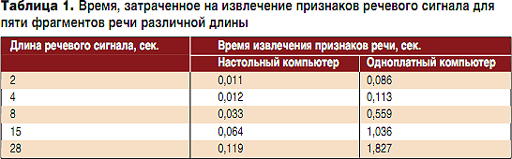
Для оценки созданной модели системы все измерения проводились как на встраиваемом устройстве, так и на настольном компьютере (Intel Core i7-4770K CPU @ 3.50 ГГц, 16 Гбайт ОЗУ, Ubuntu 13.10 64-bit) с установленной платформой ALIZE аналогичной версии для одинаковых речевых фрагментов. В таблице 1 отображено время, затраченное на извлечение признаков речевого сигнала (60 параметров на один вектор) для пяти фрагментов речи различной длины.
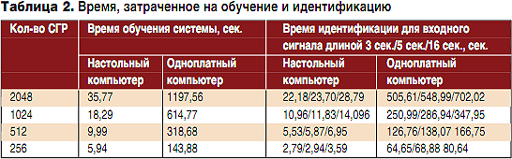
В таблице 2 представлено время, затраченное на обучение (генерацию УФМ и голосовых моделей для каждого диктора) и идентификацию в зависимости от количества СГР для системы с множеством из десяти дикторов.
На рисунке изображен процент ошибок идентификации (ложная идентификация и отказ в идентификации) в зависимости от количества СГР в голосовой модели диктора для системы с множеством из десяти дикторов при неизменном пороговом значении, установленном по умолчанию. Модель используемой системы верификации/ идентификации является текстонезависимой. Поэтому в качестве идентифицируемого речевого сигнала использовалась речь диктора, присутствующего во множестве, но с произвольными словами, т.е. с фразами, не участвующими ранее в обучении системы.

По наблюдению автора, чем больше длительность идентифицируемого речевого сигнала, тем ниже процент ошибок системы, при этом время идентификации увеличивается. При сравнении времени обработки речевого сигнала для одноплатного и настольного компьютера можно заметить, что встраиваемое устройство работает в несколько раз медленнее. В этой ситуации для уменьшения времени создания эталонных моделей имеет смысл использование настольного компьютера. Затем сгенерированные файлы моделей переносятся на встраиваемое устройство для их дальнейшего применения в процессе идентификации. Однако использование одноплатного компьютера в качестве системы идентификации диктора в реальном масштабе времени без дополнительной оптимизации, по мнению автора, невозможно. Необходима как аппаратная (например, использование более быстрой постоянной памяти), так и программная оптимизация путем конфигурирования параметров операционной системы и платформы ALIZE. Уменьшение же количества СГР в голосовой модели для увеличения производительности системы смысла не имеет, т.к. это приводит к значительному увеличению ошибок ложной идентификации. Оптимальным, по мнению автора, является значение СГР, равное 1024. Следует также отметить, что верификация речи не требует проверки подобия входного речевого сигнала для каждой модели диктора во множестве. Для верификации достаточно определить коэффициент подобия только для одной голосовой модели, на идентичность которой претендует верифицируемый диктор. В этом случае будет значительно легче определить параметры системы для ее работы в реальном масштабе времени с приемлемым уровнем ошибок верификации.
В заключение отметим, что с учетом постоянно увеличивающейся производительности встраиваемых устройств1 задачу идентификации речи на встраиваемых устройствах в скором времени можно будет свободно решать без использования дополнительных оптимизаций и ущерба для качества идентификации.
Литература
Опубликовано: Журнал "Технологии и средства связи" #2, 2016
Посещений: 4375
Автор
| |||
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
