
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣
ąøą░čĆąĖčüą░ ą£ąĄąĮčīčłąĖą║ąŠą▓ą░
菹║ąŠąĮąŠą╝ąĖč湥čüą║ąĖą╣ čüąŠą▓ąĄčéąĮąĖą║
ą┤ąĄą┐ą░čĆčéą░ą╝ąĄąĮčéą░ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝
ąæą░ąĮą║ą░ ąĀąŠčüčüąĖąĖ, ą║.čä-ą╝.ąĮ., ą┤ąŠčåąĄąĮčé ą£ąśąĀąŁąÉ
ą×čüąŠą▒ąĄąĮąĮąŠčüčéčīčÄ čĆą░ą▒ąŠčéčŗ čüąĖčüč鹥ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮčŗ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, čüąŠą▒čĆą░ąĮąĮąŠą╣ ąŠčé ą┐ąŠą┤ą▓ąĄą┤ąŠą╝čüčéą▓ąĄąĮąĮčŗčģ ą║čĆčāą┐ąĮąŠą╣ čüčéčĆčāą║čéčāčĆąĄ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖą╣ ą▓ ą▓ąĖą┤ąĄ 菹╗ąĄą║čéčĆąŠąĮąĮčŗčģ ąŠčéč湥č鹊ą▓, čÅą▓ą╗čÅąĄčéčüčÅ č鹊, čćč鹊 ą▓čüąĄ čĆą░čüč湥čéčŗ, ą║čĆąŠą╝ąĄ ą║ąŠčĆčĆąĄą╗čÅčåąĖąŠąĮąĮčŗčģ čäčāąĮą║čåąĖą╣, ą┐čĆąŠą▓ąŠą┤čÅčéčüčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą┐ąŠą┤ą▓ąĄą┤ąŠą╝čüčéą▓ąĄąĮąĮąŠą╣ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĄąĄ čüąŠą▒čüčéą▓ąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ (ą╗ąĖą▒ąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą╗ąĖą▒ąŠ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ą┐ąĄčĆąĖąŠą┤ąŠą▓ ą▓čĆąĄą╝ąĄąĮąĖ). ą¤ąŠčŹč鹊ą╝čā ą▒ąŠą╗čīčłąŠąĄ čćąĖčüą╗ąŠ čĆą░čüč湥č鹊ą▓ ą╝ąŠąČąĮąŠ ą┐čĆąŠą▓ąŠą┤ąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ą┐čĆąĖč湥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▒čāą┤čāčé, ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝, ą░ą╗ą│ąŠčĆąĖčéą╝čŗ čĆą░ą▒ąŠčéčŗ čü ą╝ą░čéčĆąĖčåą░ą╝ąĖ, čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖąĄ ą║ąŠč鹊čĆčŗčģ čģąŠčĆąŠčłąŠ ąĖąĘčāč湥ąĮąŠ ąĖ ąŠą┐ąĖčüą░ąĮąŠ čĆąŠčüčüąĖą╣čüą║ąĖą╝ąĖ čāč湥ąĮčŗą╝ąĖ. ą¤ąŠčŹč鹊ą╝čā ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ąĮą░ą┐ąĖčüą░ąĮąĮą░čÅ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ą╝ąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ ą╝ą░čéčĆąĖčćąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ čéą░ ąČąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ą░, ąĮą░ą┐ąĖčüą░ąĮąĮą░čÅ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ čüčĆąĄą┤čüčéą▓ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ą┐čĆąŠą╝čŗčłą╗ąĄąĮąĮąŠą╣ ą┐ą╗ą░čéč乊čĆą╝čŗ, ą║ąŠč鹊čĆą░čÅ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ. ąØąŠ, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, ą┐čĆąŠą╝čŗčłą╗ąĄąĮąĮčŗąĄ ą┐ą╗ą░čéč乊čĆą╝čŗ čéą░ą║ ąČąĄ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░čÄčé ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąĖ ąĘą░ą┐čāčüą║ą░čÄčé ąĖčģ ąĮą░ ąŠą┤ąĮąŠą╝ čäąĖąĘąĖč湥čüą║ąŠą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ą║ą░ą║ ąĖ čåąĄą╗čŗą╣ čĆčÅą┤ ą▓ąĖčĆčéčāą░ą╗čīąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓.

ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▓čüąĄ ąŠą┐ąĄčĆą░čåąĖąĖ c ą┤ą░ąĮąĮčŗą╝ąĖ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ąĖčģ ą▓ ąźąö ąĖ ą┐čĆąĖ ą▓čŗą│čĆčāąĘą║ąĄ ąĖąĘ ąĮąĄą│ąŠ čéą░ą║ąČąĄ čģąŠčĆąŠčłąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░čÄčéčüčÅ. ąÆ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ą║ąŠą╝ą┐ą╗ąĄą║čü ą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓ čüčĆąĄą┤ąĮąĄą│ąŠ ą║ą╗ą░čüčüą░ čéą░ą║ąŠą▓, čćč鹊 ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąĄą┤ąĖąĮąŠą│ąŠ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ čģčĆą░ąĮąĖą╗ąĖčēą░ ą┤ą░ąĮąĮčŗčģ ą▓ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ, ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąĖčüč鹥ą╝ ą║ąŠč鹊čĆąŠą╣ ą▓ąĄą╗ąĖą║ąŠ, ąĮą░ ąĘą░ą│čĆčāąĘą║čā ą┤ą░ąĮąĮčŗčģ ą▓ čģčĆą░ąĮąĖą╗ąĖčēąĄ čéčĆą░čéąĖčéčüčÅ ąŠč湥ąĮčī ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ą▓ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ ą╝ą░čéčĆąĖčåą░ čüą▓čÅąĘąĖ čŹčéąĖčģ čüąĖčüč鹥ą╝ ąĖą╝ąĄąĄčé čĆą░ąĮą│ ą▒ąŠą╗ąĄąĄ čłąĄčüčéąĮą░ą┤čåą░čéąĖ.
ą¤ąŠčŹč鹊ą╝čā ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ąĖčēąĄčé ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠąĄ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ čåąĄąĮčŗ ąĖ ą║ą░č湥čüčéą▓ą░ ą┐čĆąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĖ ą┐ą░čĆą║ą░ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ č鹥čģąĮąĖą║ąĖ, ą┤ąŠą╗ąČąĮą░ ą┐čĆąĄą┤čāčüą╝ą░čéčĆąĖą▓ą░čéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ ą▓ čĆąĄąČąĖą╝ąĄ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ. ąŁčéą░ č鹥čģąĮąŠą╗ąŠą│ąĖčÅ čĆą░ąĮąĄąĄ ą▒čŗą╗ą░ ąŠą┤ąĮąŠą╣ ąĖąĘ ąŠčüąĮąŠą▓ąĮčŗčģ ą▓ čĆą░ą╝ą║ą░čģ ą┐čĆąŠąĄą║čéą░ "ąŁą╗čīą▒čĆčāčü-2" ąØąśąÆą” ą£ąōąŻ, ąĘą░č鹥ą╝, ąĮą░čćąĖąĮą░čÅ čü 2000 ą│., čŹčéą░ č鹥ą╝ą░ ą▒čŗą╗ą░ čĆąĄą░ąĮąĖą╝ąĖčĆąŠą▓ą░ąĮą░ čĆčÅą┤ąŠą╝ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖčģ ąĖąĮčüčéąĖčéčāč鹊ą▓ ąĀąż ą▓ čĆą░ą╝ą║ą░čģ ą┐čĆąŠąĄą║čéą░ ąĪąÜąśąż.
ąÆąŠąĘą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░ąĮąĖąĄ ą│ąĄč鹥čĆąŠą│ąĄąĮąĮčŗčģ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮčŗčģ ą║ąŠą╝ą┐ą╗ąĄą║čüąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░čéčī ą░ą╗ą│ąŠčĆąĖčéą╝čŗ ą┐čĆąŠą│čĆą░ą╝ą╝, ąĮą░ą┐ąĖčüą░ąĮąĮčŗčģ ąĮą░ čÅąĘčŗą║ą░čģ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ, čéą░ą║ąĖčģ ą║ą░ą║ ąĪ, ąĪ++, ążąŠčĆčéčĆą░ąĮ ąĖ čé.ą┐.
ąÆ čüąĖčüč鹥ą╝ąĮąŠą╝ ą¤ą× ą┤ą░ąĮąĮčŗčģ čüčāą┐ąĄčĆą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓, ą×ąĪ ą║ąŠč鹊čĆčŗčģ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠč鹥č湥čüčéą▓ąĄąĮąĮąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ, ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ąŠčéą╗ą░ąČąĄąĮąĮčŗąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ ą┤ą╗čÅ čüąĖčüč鹥ą╝ ąŠč湥čĆąĄą┤ąĄą╣ ą▓ čüąĖčüč鹥ą╝ąĄ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ.
ąÆ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝ ą¤ą× ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ čüč湥čéą░, ą░ čéą░ą║ąČąĄ čüčéą░ąĮą┤ą░čĆčéąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ ą║ą╗ą░čüč鹥čĆąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ čüąĄą╝ąĄą╣čüčéą▓ą░ ąĪąÜąśąż.
ąĪąĖčüč鹥ą╝ą░ ąĘą░čēąĖčéčŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ąĮąĄ č鹊ą╗čīą║ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ąĖ, ąĮąŠ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ąĖ čüčĆąĄą┤čüčéą▓ą░ą╝ąĖ.
ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╝ ąŠč湥ą▓ąĖą┤ąĮčŗą╝ ąĮąĄą┤ąŠčüčéą░čéą║ąŠą╝ čÅą▓ą╗čÅąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄą╝ąŠą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą▓ąĄąĮčéąĖą╗čīąĮąŠą╣ ą╝ą░čéčĆąĖčåčŗ FPGA (Field Programmable Gate Array) ŌĆō ą┐ąŠą╗čāą┐čĆąŠą▓ąŠą┤ąĮąĖą║ąŠą▓ąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą┐ąŠčüą╗ąĄ ąĖąĘą│ąŠč鹊ą▓ą╗ąĄąĮąĖčÅ, ą▓ č鹊ą╝ čćąĖčüą╗ąĄ ąĖ ąĖąĘą▓ąĮąĄ č湥čĆąĄąĘ čüąĄčéąĖ ą╗čÄą▒ąŠą╣ čüą▓čÅąĘąĖ. ąŁč鹊 ąĮąĄą┐čĆąĖąĄą╝ą╗ąĄą╝ąŠ ą┐čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą▓čŗčüąŠą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąĖčüč鹥ą╝, ą░ ąĖą╝ąĄąĮąĮąŠ čéą░ą║ąŠą╣ čāčĆąŠą▓ąĄąĮčī ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą▓ ąæą░ąĮą║ąĄ ąĀąŠčüčüąĖąĖ. ąØąŠ čéą░ą║ ą║ą░ą║ ą╝ąĖą║čĆąŠčüčģąĄą╝čŗ ą▓ ą┤ą░ąĮąĮčŗčģ ą║ąŠą╝ą┐čīčÄč鹥čĆą░čģ ŌĆō ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé ąÉą¤ąÜ, ąĮą░ ą║ąŠč鹊čĆčŗą╣ ąŠčéčüčāčéčüčéą▓čāąĄčé ąĖąĮč鹥ą╗ą╗ąĄą║čéčāą░ą╗čīąĮą░čÅ čüąŠą▒čüčéą▓ąĄąĮąĮąŠčüčéčī, č鹊 ą▓ą┐ąŠą╗ąĮąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ ą▓ čĆą░ą╝ą║ą░čģ čŹč鹊ą│ąŠ ą┐čĆąŠąĄą║čéą░ ąĖąĘą▒ą░ą▓ąĖčéčīčüčÅ ąŠčé ą┤ą░ąĮąĮąŠą│ąŠ ąĮąĄą┤ąŠčüčéą░čéą║ą░.
ą¤ąŠ ą┐čĆąĖąĘąĮą░ą║ą░ą╝ ąĮą░ą╗ąĖčćąĖčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ą▓ ą┐ąŠč鹊ą║ą░čģ ą║ąŠą╝ą░ąĮą┤ ąĖ ą┤ą░ąĮąĮčŗčģ ą▓ 70-ąĄ ą│ą│. XX ą▓ąĄą║ą░ ą£ą░ą╣ą║ą╗ąŠą╝ ążą╗ąĖąĮąĮąŠą╝ ą▒čŗą╗ą░ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮą░ ą║ą╗ą░čüčüąĖčäąĖą║ą░čåąĖčÅ ą░čĆčģąĖč鹥ą║čéčāčĆ ąŁąÆą£:
ą×ąÜą×ąö ŌĆō ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮą░čÅ čüąĖčüč鹥ą╝ą░ čü ąŠą┤ąĖąĮąŠčćąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą║ąŠą╝ą░ąĮą┤ ąĖ ąŠą┤ąĖąĮąŠčćąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ (Single Instruction stream over a Single Data stream ŌĆō SISD);
ą×ąÜą£ąö ŌĆō ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮą░čÅ čüąĖčüč鹥ą╝ą░ čü ąŠą┤ąĖąĮąŠčćąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą║ąŠą╝ą░ąĮą┤ ąĖ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ (Single Instruction, Multiple Data ŌĆō SIMD);
ą£ąÜą×ąö ŌĆō ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮą░čÅ čüąĖčüč鹥ą╝ą░ čü ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą║ąŠą╝ą░ąĮą┤ ąĖ ąŠą┤ąĖąĮąŠčćąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ (Multiple Instruction Single Data ŌĆō MISD);
ą£ąÜą£ąö ŌĆō ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮą░čÅ čüąĖčüč鹥ą╝ą░ čü ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą║ąŠą╝ą░ąĮą┤ ąĖ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ (Multiple Instruction Multiple Data ŌĆō MIMD).
ą¤čĆąĖą╝ąĄčĆąŠą╝ SIMD čÅą▓ą╗čÅąĄčéčüčÅ ą▓ąĄą║č鹊čĆąĮą░čÅ ą░čĆčģąĖč鹥ą║čéčāčĆą░. ąÜ MISD, čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ąŠą│ąŠą▓ąŠčĆą║ą░ą╝ąĖ, ą╝ąŠąČąĮąŠ ąŠčéąĮąĄčüčéąĖ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĮčŗąĄ ąŁąÆą£. ąÜą╗ą░čüčü MIMD ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒čÅ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗąĄ čüąĖčüč鹥ą╝čŗ, ą│ą┤ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ ą┤ą░ąĮąĮčŗčģ.

ąĀąŠčüčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠą│čĆą░ąĮąĖč湥ąĮ ą▓ąĮąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆąŠčüčéą░ čćąĖčüą╗ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, čéą░ą║ ą║ą░ą║, ąĮą░čćąĖąĮą░čÅ čü ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ąĖčģ čćąĖčüą╗ą░, ą▓čĆąĄą╝čÅ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠąĄ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ čüąĖčüč鹥ą╝čŗ, ą▒čāą┤ąĄčé ą┐čĆąĄą▓čŗčłą░čéčī ą▓čĆąĄą╝čÅ čĆą░čüč湥č鹊ą▓. ąŁč鹊 ąĮą░ą║ą╗ą░ą┤čŗą▓ą░ąĄčé ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ ąĮą░ ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄą╝ąŠčüčéčī ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ čüąĖčüč鹥ą╝čŗ, č鹊 ąĄčüčéčī čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čćąĖčüą╗ą░ ą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ąĮąŠą▓čŗčģ čāąĘą╗ąŠą▓ ą▓ čüąĖčüč鹥ą╝čā ą▒čāą┤ąĄčé čāą▓ąĄą╗ąĖčćąĖą▓ą░čéčī ą▓čĆąĄą╝čÅ čĆą░čüč湥čéą░ ąĘą░ą┤ą░čćąĖ, ą░ ąĮąĄ čāą╝ąĄąĮčīčłą░čéčī ąĄą│ąŠ.
ąŁą║čüą┐ąĄčĆąĖą╝ąĄąĮčéą░ą╗čīąĮąŠ ą┐ąŠą╗čāč湥ąĮąĮčŗą╣ ąĘą░ą║ąŠąĮ ąÉą╝ą┤ą░ą╗ą░ čāčéą▓ąĄčƹȹ┤ą░ąĄčé, čćč鹊 čāčüą║ąŠčĆąĄąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĘą░ čüč湥čé čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ ąĄąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮą░ ą╝ąĮąŠąČąĄčüčéą▓ąĄ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗ąĄą╣ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ ą▓čĆąĄą╝ąĄąĮąĄą╝, ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╝ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĄąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ąĢčüą╗ąĖ ą┐čĆąĖ čĆąĄčłąĄąĮąĖąĖ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ ąĘą░ą┤ą░čćąĖ ąĄąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ čéą░ą║ąŠą▓, čćč鹊 ą┤ąŠą╗čÅ α ąŠčé ąŠą▒čēąĄą│ąŠ ąŠą▒čŖąĄą╝ą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮą░ č鹊ą╗čīą║ąŠ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╝ąĖ čĆą░čüč湥čéą░ą╝ąĖ, ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą┤ąŠą╗čÅ 1-α ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮą░ ą┐ąŠą╗ąĮąŠčüčéčīčÄ, č鹊 ąĄčüčéčī ą▓čĆąĄą╝čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą▒čāą┤ąĄčé ąŠą▒čĆą░čéąĮąŠ ą┐čĆąŠą┐ąŠčĆčåąĖąŠąĮą░ą╗čīąĮąŠ čćąĖčüą╗čā ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčŗčģ čāąĘą╗ąŠą▓ p, č鹊ą│ą┤ą░ čāčüą║ąŠčĆąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮąŠ ąĮą░ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ ąĖąĘ p ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ąŠą┤ąĮąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗą╝ čĆąĄčłąĄąĮąĖąĄą╝ ąĮąĄ ą▒čāą┤ąĄčé ą┐čĆąĄą▓čŗčłą░čéčī ą▓ąĄą╗ąĖčćąĖąĮčŗ
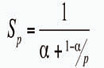
ąśąĘ č乊čĆą╝čāą╗čŗ čüą╗ąĄą┤čāąĄčé, čćč鹊 ą┐čĆąĖ ą┤ąŠą╗ąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ α ąŠą▒čēąĖą╣ ą┐čĆąĖčĆąŠčüčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĮąĄ ą╝ąŠąČąĄčé ą┐čĆąĄą▓čŗčüąĖčéčī 1/α.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, č鹊ą╗čīą║ąŠ ą░ą╗ą│ąŠčĆąĖčéą╝, ąĮąĄ čüąŠą┤ąĄčƹȹ░čēąĖą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ (α=0), ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠą╗čāčćąĖčéčī ą╗ąĖąĮąĄą╣ąĮčŗą╣ ą┐čĆąĖčĆąŠčüčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čü čĆąŠčüč鹊ą╝ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗ąĄą╣ ą▓ čüąĖčüč鹥ą╝ąĄ. ąĢčüą╗ąĖ ą┤ąŠą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ąĄ čĆą░ą▓ąĮą░ 25%, č鹊 čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ čćąĖčüą╗ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ą┤ąŠ 10 ą┤ą░ąĄčé čāčüą║ąŠčĆąĄąĮąĖąĄ ą▓ 3,077 čĆą░ąĘą░, ą░ čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ čćąĖčüą╗ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ą┤ąŠ 1000 ą┤ą░čüčé čāčüą║ąŠčĆąĄąĮąĖąĄ ą▓ 3,988 čĆą░ąĘą░.
ąŚą░ą│čĆčāąČąĄąĮąĮąŠčüčéčī, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēą░čÅ ą┤ąŠą╗čÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░čüčüčćąĖčéą░ąĮą░ ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĄą╣ č乊čĆą╝čāą╗ąĄ:
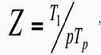
ą│ą┤ąĄ Tp ŌĆō ą▓čĆąĄą╝čÅ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖčÅ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ p ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, T1 ŌĆō ą▓čĆąĄą╝čÅ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąÆ ąĖą┤ąĄą░ą╗čīąĮąŠą╝ čüą╗čāčćą░ąĄ čĆą░ą▓ąĮą░ 1, ąĖą╗ąĖ 100%. ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ąĘą░čćą░čüčéčāčÄ ą│ąŠčĆą░ąĘą┤ąŠ ą▒ąŠą╗ąĄąĄ ąĮą░ą│ą╗čÅą┤ąĮąŠ čģą░čĆą░ą║č鹥čĆąĖąĘčāąĄčé čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ą▓ čüąĄčĆąĖąĖ ąĖčüą┐čŗčéą░ąĮąĖą╣ ą┐čĆąĖ čĆą░ąĘąĮčŗčģ p, č湥ą╝ Sp.
ą¤čĆąŠą▓ąĄą┤ąĄąĮąĮčŗą╣ ą░ąĮą░ą╗ąĖąĘ č鹥čģąĮąŠą╗ąŠą│ąĖą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┐ąŠą┤čéą▓ąĄčĆą┤ąĖą╗ ąĖčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čéčī ą▒ąŠą╗ąĄąĄ ą║ąŠčĆčĆąĄą║čéąĮčāčÄ čĆą░ą▒ąŠčéčā čģčĆą░ąĮąĖą╗ąĖčē ą┤ą░ąĮąĮčŗčģ ąĘą░ čüč湥čé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┤ą╗čÅ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ąźąö. ą¤čĆąĖ čŹč鹊ą╝ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĘą░ą║ąŠąĮą░ ąÉą╝ą┤ą░ą╗ą░ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą┤ą░čÄčēąĖčģ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ čāčüą║ąŠčĆąĄąĮąĖąĄ čŹč鹊ą╝čā ą┐čĆąŠčåąĄčüčüčā ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ąĘą░čéčĆą░čéčŗ ąĮą░ ą┤ąŠąĘą░ą║čāą┐ą║čā ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮąĖčÅ ą▓ čćą░čüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą▓ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ ąĘą░ą│čĆčāąĘą║ą░ ąźąö ą┐čĆąĖ ąĮą░čćą░ą╗čīąĮąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąŠčģąŠą┤ąĖčéčī ąĮąĄą┐čĆąĖąĄą╝ą╗ąĄą╝ąŠąĄ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ ą▓čĆąĄą╝čÅ. ąŁč鹊 ąŠčüąŠą▒ąĄąĮąĮąŠ ą▓ą░ąČąĮąŠ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ą▓ ąźąö ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ą┐ąŠčüčéčāą┐ą░čÄčēąĄą╣ ąĖąĘ ą▓ąĮąĄčłąĮąĖčģ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖą╣, čéą░ą║ ą║ą░ą║ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ąĖ ąŠčćąĖčüčéą║ą░ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠč湥ąĮčī čĆąĄčüčāčĆčüąŠąĄą╝ą║ąĖą╝ąĖ.
ąøąĖč鹥čĆą░čéčāčĆą░
ą×ą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ: ą¢čāčĆąĮą░ą╗ "ąóąĄčģąĮąŠą╗ąŠą│ąĖąĖ ąĖ čüčĆąĄą┤čüčéą▓ą░ čüą▓čÅąĘąĖ" #6, 2011
ą¤ąŠčüąĄčēąĄąĮąĖą╣: 6556
ąĪčéą░čéčīąĖ ą┐ąŠ č鹥ą╝ąĄ
ąÉą▓č鹊čĆ
| |||
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣


