
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣
ąøą░čĆąĖčüą░ ą£ąĄąĮčīčłąĖą║ąŠą▓ą░
菹║ąŠąĮąŠą╝ąĖč湥čüą║ąĖą╣ čüąŠą▓ąĄčéąĮąĖą║
ą┤ąĄą┐ą░čĆčéą░ą╝ąĄąĮčéą░ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝
ąæą░ąĮą║ą░ ąĀąŠčüčüąĖąĖ, ą║.čä.-ą╝.ąĮ., ą┤ąŠčåąĄąĮčé ą£ąśąĀąŁąÉ
ąÆ ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ čģčĆą░ąĮąĖą╗ąĖčēą░čģ ą┤ą░ąĮąĮčŗąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐čĆąĄą┤ą╝ąĄčéąĮąŠ-ąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮčŗčģ čéą░ą▒ą╗ąĖčåą░čģ čéčĆąĄčéčīąĄą╣ ąĖą╗ąĖ ą▒ąŠą╗ąĄąĄ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝čŗ.
ąØąŠčĆą╝ą░ą╗čīąĮą░čÅ č乊čĆą╝ą░ ąæąŠą╣čüą░ ŌĆō ąÜąŠą┤ą┤ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ č鹥ą╝, čćč鹊 ąŠčéąĮąŠčłąĄąĮąĖąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čéčĆąĄčéčīąĄą╣ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ ąĖ ą▓ ąĮąĄą╝ ąŠčéčüčāčéčüčéą▓čāčÄčé čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą░čéčĆąĖą▒čāč鹊ą▓ ą┐ąĄčĆą▓ąĖčćąĮąŠą│ąŠ ą║ą╗čÄčćą░ ąŠčé ąĮąĄą║ą╗čÄč湥ą▓čŗčģ ą░čéčĆąĖą▒čāč鹊ą▓.
ą×čéąĮąŠčłąĄąĮąĖąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ č湥čéą▓ąĄčĆč鹊ą╣ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ, ąĄčüą╗ąĖ ąŠąĮąŠ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ ąæąŠą╣čüą░ ŌĆō ąÜąŠą┤ą┤ą░ ąĖ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé ąĮąĄčéčĆąĖą▓ąĖą░ą╗čīąĮčŗčģ ą╝ąĮąŠą│ąŠąĘąĮą░čćąĮčŗčģ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, čĆą░ą▓ąĮąŠ ą║ą░ą║ ąĖ ąĮąĄčäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗčģ ą╝ąĮąŠą│ąŠąĘąĮą░čćąĮčŗčģ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣.
ą£ąĮąŠą│ąŠąĘąĮą░čćąĮą░čÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ąĮąĄ ą▓čüąĄą│ą┤ą░ čÅą▓ą╗čÅąĄčéčüčÅ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠą╣. ąØą░ą╗ąĖčćąĖąĄ ą▓ ąŠčéąĮąŠčłąĄąĮąĖąĖ ą╝ąĮąŠą│ąŠąĘąĮą░čćąĮčŗčģ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, ąĮąĄ čÅą▓ą╗čÅčÄčēąĖčģčüčÅ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗą╝ąĖ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčÅą╝ąĖ ąŠčé ą▓ąŠąĘą╝ąŠąČąĮąŠą│ąŠ ą║ą╗čÄčćą░, ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą░ąĮąŠą╝ą░ą╗ąĖčÅą╝ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ čéą░ą║ąĖčģ ąŠčéąĮąŠčłąĄąĮąĖą╣. ą¤ąŠčŹč鹊ą╝čā ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čÅčéčāčÄ ąĮąŠčĆą╝ą░ą╗čīąĮčāčÄ č乊čĆą╝čā.
ąóą░ą▒ą╗ąĖčåą░ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐čÅč鹊ą╣ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ, ąĄčüą╗ąĖ ąŠąĮą░ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ č湥čéą▓ąĄčĆč鹊ą╣ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ ąĖ ą╗čÄą▒ą░čÅ ą╝ąĮąŠą│ąŠąĘąĮą░čćąĮą░čÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą▓ ąĮąĄą╣ čÅą▓ą╗čÅąĄčéčüčÅ čéčĆąĖą▓ąĖą░ą╗čīąĮąŠą╣.
ą¤čÅčéą░čÅ ąĮąŠčĆą╝ą░ą╗čīąĮą░čÅ č乊čĆą╝ą░ ą▓ ą▒ąŠą╗čīčłąĄą╣ čüč鹥ą┐ąĄąĮąĖ čÅą▓ą╗čÅąĄčéčüčÅ č鹥ąŠčĆąĄčéąĖč湥čüą║ąĖą╝ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄą╝ ąĖ ą┐čĆą░ą║čéąĖč湥čüą║ąĖ ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą┐čĆąĖ čĆąĄą░ą╗čīąĮąŠą╝ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĖ ą▒ą░ąĘ ą┤ą░ąĮąĮčŗčģ. ąŁč鹊 čüą▓čÅąĘą░ąĮąŠ čüąŠ čüą╗ąŠąČąĮąŠčüčéčīčÄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čüą░ą╝ąŠą│ąŠ ąĮą░ą╗ąĖčćąĖčÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣ "ą┐čĆąŠąĄą║čåąĖąĖ ŌĆō čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ", ą┐ąŠčüą║ąŠą╗čīą║čā čāčéą▓ąĄčƹȹ┤ąĄąĮąĖąĄ ąŠ ąĮą░ą╗ąĖčćąĖąĖ čéą░ą║ąŠą╣ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ ą┤ą╗čÅ ą▓čüąĄčģ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ čüąŠčüč鹊čÅąĮąĖą╣ ąæąö.
ąØąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗąĄ čģčĆą░ąĮąĖą╗ąĖčēą░ čģą░čĆą░ą║č鹥čĆąĖąĘčāčÄčéčüčÅ ą║ą░ą║ ą┐čĆąŠčüčéčŗąĄ ą▓ čüąŠąĘą┤ą░ąĮąĖąĖ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąØąĄą┤ąŠčüčéą░čéą║ąŠą╝ čéą░ą║ąĖčģ ąźąö čÅą▓ą╗čÅąĄčéčüčÅ ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą▒ą╗ąĖčå ą║ą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ, ąĖąĘ-ąĘą░ č湥ą│ąŠ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąĮčāąČąĮąŠ ą┤ąĄą╗ą░čéčī ą▓čŗą▒ąŠčĆą║čā ąĖąĘ ą╝ąĮąŠą│ąĖčģ čéą░ą▒ą╗ąĖčå ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, čćč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čāčģčāą┤čłąĄąĮąĖčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ.
ąóą░ą║ąŠą╣ čéąĖą┐ čģčĆą░ąĮąĖą╗ąĖčē ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ čāąČąĄ ąĮąĄ ą┐ą╗ąŠčüą║ąĖąĄ čéą░ą▒ą╗ąĖčåčŗ, ą░ ą║čāą▒čŗ, čāčćąĖčéčŗą▓ą░čÄčēąĖąĄ ąĮąĄ č鹊ą╗čīą║ąŠ čĆą░ąĘą╝ąĄčĆąĮąŠčüčéąĮčŗąĄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ ą╝ąŠą┤ąĄą╗ąĖ, ąĮąŠ ąĖ ąĄąĄ ą▓ąĮčāčéčĆąĄąĮąĮčÄčÄ čüčéčĆčāą║čéčāčĆčā ą▓ ą▓ąĖą┤ąĄ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ąŠą│ąŠ ą│čĆą░čäą░ čĆą░čüčüą╗ąŠąĄąĮąĖčÅ ąĖ čüą▓čÅąĘąĮąŠčüčéąĖ.
ą×čüąĮąŠą▓ąĮčŗą╝ ą┤ąŠčüč鹊ąĖąĮčüčéą▓ąŠą╝ čĆą░ąĘą╝ąĄčĆąĮąŠčüčéąĮčŗčģ ąźąö čÅą▓ą╗čÅąĄčéčüčÅ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ čģčĆą░ąĮąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ, ą░ čéą░ą║ąČąĄ ą┐čĆąŠčüč鹊čéą░ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ą┐čĆąĖ ą░ąĮą░ą╗ąĖąĘąĄ. ą×čüąĮąŠą▓ąĮčŗąĄ ąĮąĄą┤ąŠčüčéą░čéą║ąĖ ŌĆō ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ ą┐čĆąŠčåąĄą┤čāčĆčŗ ą┐ąŠą┤ą│ąŠč鹊ą▓ą║ąĖ ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ, ą░ čéą░ą║ąČąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖąĖ čĆą░ąĘą╝ąĄčĆąĮąŠčüč鹥ą╣ ą┤ą░ąĮąĮčŗčģ.
ąĀą░ąĘą╝ąĄčĆąĮąŠčüčéąĮčŗąĄ ąźąö ąĖčüą┐ąŠą╗čīąĘčāčÄčé čüčģąĄą╝čā "ąĘą▓ąĄąĘą┤ą░" ąĖą╗ąĖ "čüąĮąĄąČąĖąĮą║ą░".
ąóą░ą║ą░čÅ čüčģąĄą╝ą░ čüąŠčüč鹊ąĖčé ąĖąĘ ą┤ą▓čāčģ čéąĖą┐ąŠą▓ čéą░ą▒ą╗ąĖčå: ąŠą┤ąĮąŠą╣ čéą░ą▒ą╗ąĖčåčŗ čäą░ą║č鹊ą▓ ŌĆō čåąĄąĮčéčĆ "ąĘą▓ąĄąĘą┤čŗ" ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čéą░ą▒ą╗ąĖčå ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ą┐ąŠ čćąĖčüą╗čā ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ą▓ ą╝ąŠą┤ąĄą╗ąĖ ą┤ą░ąĮąĮčŗčģ ŌĆō ą╗čāčćąĖ "ąĘą▓ąĄąĘą┤čŗ".
ąóą░ą▒ą╗ąĖčåą░ čäą░ą║č鹊ą▓ čÅą▓ą╗čÅąĄčéčüčÅ ąŠčüąĮąŠą▓ąĮąŠą╣ čéą░ą▒ą╗ąĖčåąĄą╣ ąźąö ąĖ čüąŠą┤ąĄčƹȹĖčé čüą▓ąĄą┤ąĄąĮąĖčÅ ąŠą▒ ąŠą▒čŖąĄą║čéą░čģ ąĖą╗ąĖ čüąŠą▒čŗčéąĖčÅčģ, čüąŠą▓ąŠą║čāą┐ąĮąŠčüčéčī ą║ąŠč鹊čĆčŗčģ ą▒čāą┤ąĄčé ą▓ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčīčüčÅ, ą░ čéą░ą║ąČąĄ čüąŠą┤ąĄčƹȹĖčé čāąĮąĖą║ą░ą╗čīąĮčŗą╣ čüąŠčüčéą░ą▓ąĮąŠą╣ ą║ą╗čÄčć, ąŠą▒čŖąĄą┤ąĖąĮčÅčÄčēąĖą╣ ą┐ąĄčĆą▓ąĖčćąĮčŗąĄ ą║ą╗čÄčćąĖ čéą░ą▒ą╗ąĖčå ąĖąĘą╝ąĄčĆąĄąĮąĖą╣.
ą¦ąĄčéčŗčĆąĄ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ą▓čüčéčĆąĄčćą░čÄčēąĖčģčüčÅ čéąĖą┐ą░ čäą░ą║č鹊ą▓:
ąöą░ąĮąĮą░čÅ čéą░ą▒ą╗ąĖčåą░ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮą░ ą▓ čüčéčĆčāą║čéčāčĆąĄ ą╝ąĮąŠą│ąŠą╝ąĄčĆąĮąŠą╣ ąæąö, ą║ąŠč鹊čĆą░čÅ čüąŠą┤ąĄčƹȹĖčé ą░čéčĆąĖą▒čāčéčŗ čüąŠą▒čŗčéąĖą╣, čüąŠčģčĆą░ąĮąĄąĮąĮčŗčģ ą▓ čéą░ą▒ą╗ąĖčåąĄ čäą░ą║č鹊ą▓. ąÉčéčĆąĖą▒čāčéčŗ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčé čüąŠą▒ąŠą╣ č鹥ą║čüč鹊ą▓čŗąĄ ąĖą╗ąĖ ąĖąĮčŗąĄ ąŠą┐ąĖčüą░ąĮąĖčÅ, ą╗ąŠą│ąĖč湥čüą║ąĖ ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĮčŗąĄ ą▓ ąŠą┤ąĮąŠ čåąĄą╗ąŠąĄ. ąŚą░ą┐ąĖčüąĖ ą▓ čéą░ą▒ą╗ąĖčåąĄ čäą░ą║č鹊ą▓ čüą▓čÅąĘą░ąĮčŗ čü ąĘą░ą┐ąĖčüčÅą╝ąĖ ą▓ čéą░ą▒ą╗ąĖčåą░čģ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ą┐ąŠ ą▓č鹊čĆąĖčćąĮąŠą╝čā ą║ą╗čÄčćčā.
ąóą░ą▒ą╗ąĖčåą░ čäą░ą║č鹊ą▓ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī čüąŠčéąĮąĖ čéčŗčüčÅčć ąĖą╗ąĖ ą┤ą░ąČąĄ ą╝ąĖą╗ą╗ąĖąŠąĮčŗ ąĘą░ą┐ąĖčüąĄą╣, ą┐čĆąĖ čŹč鹊ą╝ ą║ą░ą║ ą║ą╗čÄč湥ą▓čŗąĄ, čéą░ą║ ąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄą║ą╗čÄč湥ą▓čŗąĄ ą┐ąŠą╗čÅ ą┤ąŠą╗ąČąĮčŗ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ą▒čāą┤čāčēąĖą╝ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅą╝ OLAP-ą║čāą▒ą░. ą¤ąŠą╝ąĖą╝ąŠ čŹč鹊ą│ąŠ, čéą░ą▒ą╗ąĖčåą░ čäą░ą║č鹊ą▓ čüąŠą┤ąĄčƹȹĖčé ąŠą┤ąĮąŠ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ čćąĖčüą╗ąŠą▓čŗčģ ą┐ąŠą╗ąĄą╣, ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ ą║ąŠč鹊čĆčŗčģ ą▓ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ą▒čāą┤čāčé ą░ą│čĆąĄą│ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą░ąĮąĮčŗąĄ. ąöą╗čÅ ą╝ąĮąŠą│ąŠą╝ąĄčĆąĮąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čéą░ą▒ą╗ąĖčåčŗ čäą░ą║č鹊ą▓, čüąŠą┤ąĄčƹȹ░čēąĖąĄ ą║ą░ą║ ą╝ąŠąČąĮąŠ ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ (č鹊 ąĄčüčéčī čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čćą╗ąĄąĮą░ą╝ ąĮąĖąČąĮąĖčģ čāčĆąŠą▓ąĮąĄą╣ ąĖąĄčĆą░čĆčģąĖąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣). ąÆ čéą░ą▒ą╗ąĖčåąĄ čäą░ą║č鹊ą▓ ąĮąĄčé ąĮąĖą║ą░ą║ąĖčģ čüą▓ąĄą┤ąĄąĮąĖą╣ ąŠ č鹊ą╝, ą║ą░ą║ ą│čĆčāą┐ą┐ąĖčĆąŠą▓ą░čéčī ąĘą░ą┐ąĖčüąĖ ą┐čĆąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĖ ą░ą│čĆąĄą│ą░čéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąŁčéąĖ čüą▓ąĄą┤ąĄąĮąĖčÅ, ą▓ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą╗čÅ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ ąĖąĄčĆą░čĆčģąĖą╣ ą▓ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅčģ ą║čāą▒ą░, čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ čéą░ą▒ą╗ąĖčåą░čģ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ čéą░ą▒ą╗ąĖčåčŗ čäą░ą║č鹊ą▓ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čéą░ą▒ą╗ąĖčåčŗ čĆą░ąĘą╝ąĄčĆąĮąŠčüč鹥ą╣, čćč鹊 ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ąŠą▒ą╗ąĄą│čćą░ąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąĄą┤ą╝ąĄčéąĮčŗčģ čéą░ą▒ą╗ąĖčå čäą░ą║č鹊ą▓.
ą×ą▒čŗčćąĮąŠ ą┤ą░ąĮąĮčŗąĄ ą▓ čéą░ą▒ą╗ąĖčåą░čģ-ąĖąĘą╝ąĄčĆąĄąĮąĖčÅčģ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāą╝ąĄąĮčīčłąĖčéčī čćąĖčüą╗ąŠ čéą░ą▒ą╗ąĖčå ąĖ čüąŠą║čĆą░čéąĖčéčī ą▓čĆąĄą╝čÅ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░ ąĘą░ čüč湥čé ąĮąĄčŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ąĖčüą║ąŠą▓ąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░.
ąÆ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąĄčüčéąĖ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖčÄ čéą░ą▒ą╗ąĖčå-ąĖąĘą╝ąĄčĆąĄąĮąĖą╣, č鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčé čüčģąĄą╝čā "čüąĮąĄąČąĖąĮą║ą░".
ąöą░ąĮąĮą░čÅ čüčģąĄą╝ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĮą░ąĘą▓ą░ąĮąĖąĄ ąĘą░ č乊čĆą╝čā ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ čüčģąĄą╝čŗ čéą░ą▒ą╗ąĖčå ą▓ ą╝ąĮąŠą│ąŠą╝ąĄčĆąĮąŠą╣ ąæąö. ąóą░ą║ ąČąĄ ą║ą░ą║ ąĖ ą▓ čüčģąĄą╝ąĄ "ąĘą▓ąĄąĘą┤ą░", čüčģąĄą╝ą░ "čüąĮąĄąČąĖąĮą║ą░" ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮą░ čåąĄąĮčéčĆą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą╣ čéą░ą▒ą╗ąĖčåąĄą╣ čäą░ą║č鹊ą▓, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü čéą░ą▒ą╗ąĖčåą░ą╝ąĖ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣. ą×čéą╗ąĖčćąĖąĄą╝ čÅą▓ą╗čÅąĄčéčüčÅ č鹊, čćč鹊 ą▓ ąĮąĄą╣ čéą░ą▒ą╗ąĖčåčŗ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ čü čĆčÅą┤ąŠą╝ ą┤čĆčāą│ąĖčģ čüą▓čÅąĘą░ąĮąĮčŗčģ ąĖąĘą╝ąĄčĆąĖč鹥ą╗čīąĮčŗčģ čéą░ą▒ą╗ąĖčå, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą▓ čüčģąĄą╝ąĄ "ąĘą▓ąĄąĘą┤ą░" čéą░ą▒ą╗ąĖčåčŗ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ čü ą║ą░ąČą┤čŗą╝ ąĖąĘą╝ąĄčĆąĄąĮąĖąĄą╝, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ ą▓ ą▓ąĖą┤ąĄ ąĄą┤ąĖąĮąŠą╣ čéą░ą▒ą╗ąĖčåčŗ, ą▒ąĄąĘ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ ąĮą░ čüą▓čÅąĘą░ąĮąĮčŗąĄ čéą░ą▒ą╗ąĖčåčŗ ą▓ čüčģąĄą╝ąĄ "čüąĮąĄąČąĖąĮą║ą░". ą¦ąĄą╝ ą▒ąŠą╗čīčłąĄ čüč鹥ą┐ąĄąĮčī ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ čéą░ą▒ą╗ąĖčå ąĖąĘą╝ąĄčĆąĄąĮąĖą╣, č鹥ą╝ čüą╗ąŠąČąĮąĄąĄ ą▓čŗą│ą╗čÅą┤ąĖčé čüčéčĆčāą║čéčāčĆą░ čüčģąĄą╝čŗ "čüąĮąĄąČąĖąĮą║ą░". ąĪąŠąĘą┤ą░ą▓ą░ąĄą╝čŗą╣ "čŹčäč乥ą║čé čüąĮąĄąČąĖąĮą║ąĖ" ąĘą░čéčĆą░ą│ąĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ čéą░ą▒ą╗ąĖčåčŗ ąĖąĘą╝ąĄčĆąĄąĮąĖą╣ ąĖ ąĮąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ ą║ čéą░ą▒ą╗ąĖčåą░ą╝ čäą░ą║č鹊ą▓.
ąĪčģąĄą╝ą░ "čüąĮąĄąČąĖąĮą║ą░", čéą░ą║ ąČąĄ ą║ą░ą║ ąĖ čüčģąĄą╝ą░ "ąĘą▓ąĄąĘą┤ą░", ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ ą▓ čéą░ą║ąĖčģ ąźąö, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čüą║ąŠčĆąŠčüčéčī ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą▒ąŠą╗ąĄąĄ ą▓ą░ąČąĮą░, č湥ą╝ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī ąĖčģ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ.
ąĪčģąĄą╝ą░ "čüąĮąĄąČąĖąĮą║ą░" ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čüą╗čāčćą░ąĄą▓ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮąŠą│ąŠ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ąĘą░ą┐čĆąŠčüąŠą▓, ą║ąŠč鹊čĆčŗą╣ ą▓ ą▒ąŠą╗čīčłąĄą╣ čüč鹥ą┐ąĄąĮąĖ ąĖąĘąŠą╗ąĖčĆčāąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ ąŠčé ą┤ąĄčéą░ą╗čīąĮąŠą╣ čüčéčĆčāą║čéčāčĆčŗ čéą░ą▒ą╗ąĖčå, ą░ čéą░ą║ąČąĄ ą┤ą╗čÅ čüčĆąĄą┤čŗ čü ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ąĘą░ą┐čĆąŠčüąŠą▓ čüą╗ąŠąČąĮąŠą╣ čüčéčĆčāą║čéčāčĆčŗ.
ąĪčāčēąĄčüčéą▓čāąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ čéąĖą┐ąŠą▓čŗčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ą║ąŠąĮčåąĄą┐čéčāą░ą╗čīąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ąÜąźąö, ą║ąŠč鹊čĆčŗąĄ, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, ąĮąĄą╗čīąĘčÅ č湥čéą║ąŠ ąŠčéąĮąĄčüčéąĖ ą║ ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╝ (ą╝ąŠą┤ąĄą╗čī ąśąĮą╝ąŠąĮą░) ąĖ čĆą░ąĘą╝ąĄčĆąĮąŠčüčéąĮčŗą╝ ąźąö (ą╝ąŠą┤ąĄą╗čī ąÜąĖą╝ą▒ą░ą╗ą╗ą░):
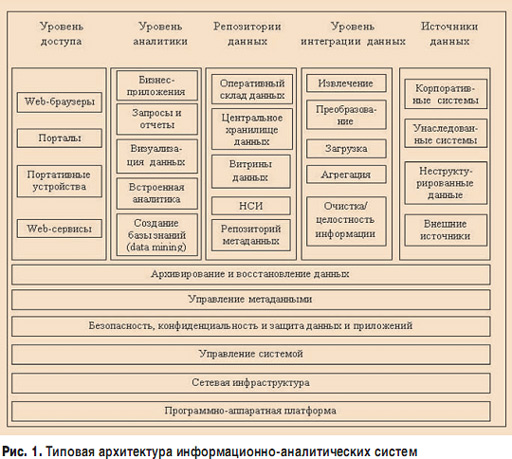
ą×čüčéą░ąĮąŠą▓ąĖą╝čüčÅ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ ąĮą░ ą║ą░ąČą┤ąŠą╝ ąĖąĘ ą▓čŗčłąĄą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓ ąźąö, ą┐čĆąŠčĆąĖčüąŠą▓ą░ą▓ ąĖčģ ą░čĆčģąĖč鹥ą║čéčāčĆčā ą║ą░ą║ ą┐čĆąŠąĄą║čåąĖčÄ ąĮą░ čéąĖą┐ąŠą▓čāčÄ ą░čĆčģąĖč鹥ą║čéčāčĆčā ąśąÉąĪ (čüą╝. čĆąĖčü. 1).
ąŁč鹊 ąŠą┤ąĮą░ ąĖąĘ ą╝ąŠą┤ąĄą╗ąĄą╣ ąźąö, ą▓ ą║ąŠč鹊čĆąŠą╝ ą┤ą░ąĮąĮčŗąĄ čģčĆą░ąĮčÅčéčüčÅ ą▓ čĆą░ąĘąĮčŗčģ ąæąö ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ čĆą░ąĘą╗ąĖčćąĮčŗčģ ąĪąŻąæąö, ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĮčŗčģ ą┐ąŠčüčĆąĄą┤čüčéą▓ąŠą╝ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ čü ąĄą┤ąĖąĮąŠą╣ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ą╝ąŠą┤ąĄą╗čīčÄ ą┤ą░ąĮąĮčŗčģ.
ą×čüąĮąŠą▓ąŠą╣ ą▓ąĖčĆčéčāą░ą╗čīąĮąŠą│ąŠ ąźąö čÅą▓ą╗čÅąĄčéčüčÅ čĆąĄą┐ąŠąĘąĖč鹊čĆąĖą╣ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ąŠą┐ąĖčüčŗą▓ą░ąĄčé ąĖčüč鹊čćąĮąĖą║ąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ąĘą░ą┐čĆąŠčüčŗ ąĪąŻąæąö ąĮą░ čćč鹥ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖ ą┐čĆąŠčåąĄą┤čāčĆčŗ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ. ąÆ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ ą▓ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮąŠ-ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąŠą╣ čüąĖčüč鹥ą╝ąĄ, čĆą░ą▒ąŠčéą░čÄčēąĄą╣ čü čéą░ą║ąĖą╝ ąźąö, ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ, ą║ąŠąĮąĄčćąĮčŗąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ čäą░ą║čéąĖč湥čüą║ąĖ čĆą░ą▒ąŠčéą░čÄčé čü ąĖčüč鹊čćąĮąĖą║ą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ ąĮą░ą┐čĆčÅą╝čāčÄ (čüą╝. čĆąĖčü. 2).
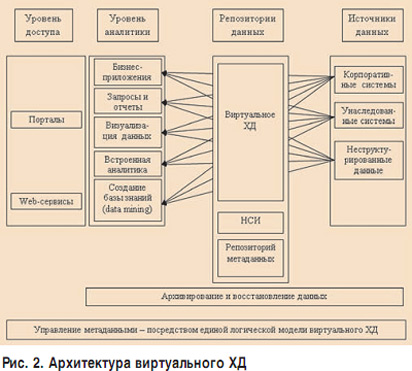
ąÆąĖčĆčéčāą░ą╗čīąĮčŗąĄ ąźąö ą╝ąŠąČąĮąŠ čĆą░ąĘą┤ąĄą╗ąĖčéčī ąĮą░ ą┤ą▓ąĄ ą║ą░č鹥ą│ąŠčĆąĖąĖ, ąŠčéą╗ąĖčćą░čÄčēąĖąĄčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ čüą╗ąŠąČąĮąŠčüčéčīčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ŌĆō čü čåąĄąĮčéčĆą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╝ ą▓ąĄą┤ąĄąĮąĖąĄą╝ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ ąĖ čü ą┤ąĄčåąĄąĮčéčĆą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╝ ą▓ąĄą┤ąĄąĮąĖąĄą╝ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ.
ąÆ čüą╗čāčćą░ąĄ čüą╗ą░ą▒ąŠą╣ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čĆą░ąĘąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓ čŹč鹊čé ą▓ą░čĆąĖą░ąĮčé ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐čĆąĖąĄą╝ą╗ąĄą╝čŗą╣, čéą░ą║ ą║ą░ą║ ąŠą▒ą╗ą░ą┤ą░ąĄčé čåąĄą╗čŗą╝ čĆčÅą┤ąŠą╝ čÅą▓ąĮčŗčģ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓: ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗąĄ ąĘą░čéčĆą░čéčŗ ąĖ čĆą░ą▒ąŠčéą░ čü ą┤ą░ąĮąĮčŗą╝ąĖ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą▒ąĄąĘ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗčģ čüą╗ąŠąĄą▓. ąØąŠ ąĄčüčéčī ąĖ ą┤ą▓ą░ ąŠč湥ą▓ąĖą┤ąĮčŗčģ ąĮąĄą┤ąŠčüčéą░čéą║ą░ ą▓ąĖčĆčéčāą░ą╗čīąĮčŗčģ ąźąö:
ąÆąĖčéčĆąĖąĮą░ ą┤ą░ąĮąĮčŗčģ ŌĆō čŹč鹊 ąĮą░ą▒ąŠčĆ č鹥ą╝ą░čéąĖč湥čüą║ąĖ čüą▓čÅąĘą░ąĮąĮčŗčģ ąæąö, čüąŠą┤ąĄčƹȹ░čēąĖą╣ č鹥ą╝ą░čéąĖč湥čüą║ąĖ ąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĖč鹊ą│ąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ, ą▓ ą║ą░č湥čüčéą▓ąĄ čĆą░čüč湥čéąĮčŗčģ ą▓ąĄą╗ąĖčćąĖąĮ ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▓čüąĄčģ ąæąö.
ąĢčüą╗ąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąŠą┤ąĮąĖčģ ąĖ č鹥čģ ąČąĄ ąæąö ą┐čĆąŠąĄą║čéąĖčĆčāąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓ąĖčéčĆąĖąĮ ą┤ą░ąĮąĮčŗčģ, č鹊 ą▓ąŠąĘą╝ąŠąČąĮčŗ ą┤ą▓ą░ čüą╗čāčćą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┤ą░ąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ŌĆō ąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ąĖ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ.
ąÆ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ čŹč鹊 ąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ, č鹊 ąĄčüčéčī ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ, ą▓ ą║ąŠč鹊čĆčŗčģ ąŠą┤ąĮąĖ ąĖ č鹥 ąČąĄ ąĖč鹊ą│ąŠą▓čŗąĄ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą┐ąŠą╗čāčćą░čÄčéčüčÅ ą▓ čĆą░ąĘąĮčŗčģ ą▓ąĖčéčĆąĖąĮą░čģ ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą║ąŠąĮąĄčćąĮčŗąĄ ąĖ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗąĄ čĆą░čüč湥čéąĮčŗąĄ ą▓ąĄą╗ąĖčćąĖąĮčŗ ąĖąĘ ą┤čĆčāą│ąĖčģ ą▓ąĖčéčĆąĖąĮ ą┤ą░ąĮąĮčŗčģ, č鹊 čåąĄą╗ąĄčüąŠąŠą▒čĆą░ąĘąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čéą░ą║ąŠą│ąŠ ą▓ą░čĆąĖą░ąĮčéą░ ą┐čĆąĖ ą╝ą░čéčĆąĖčåąĄ čüą▓čÅąĘąĖ čĆą░ąĮą│ą░ ąĮąĄ ą▒ąŠą╗ąĄąĄ 3, čéą░ą║ ą║ą░ą║ ą▓ ą┐čĆąŠčéąĖą▓ąĮąŠą╝ čüą╗čāčćą░ąĄ ą┐čĆą░ą║čéąĖą║ą░ čüąŠąĘą┤ą░ąĮąĖčÅ ąźąö ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĮąĄą║ąŠčĆčĆąĄą║čéąĮąŠ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ ąŠą▒čĆą░čéąĮčŗą╝ ąĘą░ą┤ą░čćą░ą╝ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĖčüč鹊čćąĮąĖą║ą░ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ąĖč鹊ą│ą░ą╝.
ąØąĄąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ŌĆō čŹč鹊 ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ, ą▓ ą║ą░ąČą┤ąŠą╣ ąĖąĘ ą║ąŠč鹊čĆčŗčģ ą╗ąĖą▒ąŠ čĆą░čüč湥čéąĮčŗąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ ąĮąĄ čüą▓čÅąĘą░ąĮčŗ ą╝ąĄąČą┤čā čüąŠą▒ąŠą╣, ą╗ąĖą▒ąŠ ąŠą┤ąĮąĖ ąĖ č鹥 ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą║ ą┤ą░ąĮąĮčŗą╝, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗą╝ ą┐ąŠ ą│ąĄąŠą│čĆą░čäąĖč湥čüą║ąŠą╝čā, ą▓čĆąĄą╝ąĄąĮąĮąŠą╝čā ąĖą╗ąĖ ą║ą░ą║ąŠą╝čā-ą╗ąĖą▒ąŠ ą┤čĆčāą│ąŠą╝čā ą┐čĆąĖąĘąĮą░ą║čā ą┐ąŠą╗ąĮąŠčüčéčīčÄ (čüą╝. čĆąĖčü. 3). ąöą░ąĮąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 č鹊ą╗čīą║ąŠ ą▓ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ čĆą░ąĘąĮčŗčģ ą▓ąĖčéčĆąĖąĮą░čģ čüą▓čÅąĘą░ąĮčŗ č鹊ą╗čīą║ąŠ ą┐ąŠ ą┐ąĄčĆą▓ąĖčćąĮąŠą╝čā ą║ą╗čÄčćčā, ąĖ, ą║čĆąŠą╝ąĄ č鹊ą│ąŠ, čéčĆą░ąĮąĘą░ą║čåąĖąŠąĮąĮą░čÅ ąĖ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░ąĘąĮąĄčüąĄąĮčŗ ąĮą░ čĆą░ąĘąĮčŗąĄ ą░ą┐ą┐ą░čĆą░čéąĮąŠ-ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠą╝ą┐ą╗ąĄą║čüčŗ.
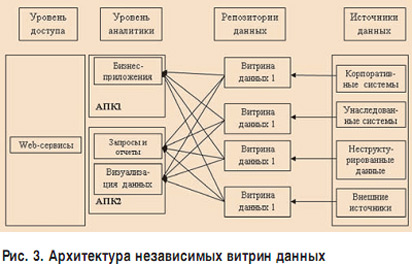
ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą▓ąĖčéčĆąĖąĮ ą▒čŗą╗ąŠ ą┐ąĄčĆą▓ąŠą╣ čĆąĄą░ą║čåąĖąĄą╣ ąĮą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąŠą╣ ąĖ čéčĆą░ąĮąĘą░ą║-čåąĖąŠąĮąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąĮčāąČą┤ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüąĖčüč鹥ą╝.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮąŠą│ąŠ ą▓ą░čĆąĖą░ąĮčéą░ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ŌĆō ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą▓ąĖčéčĆąĖąĮ ą┤ą░ąĮąĮčŗčģ ŌĆō čāą┐čĆąŠčēą░ąĄčé ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ, ąĮąŠ čāčüą╗ąŠąČąĮčÅąĄčé 菹║čüą┐ą╗čāą░čéą░čåąĖčÄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ-ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą║ąŠą╝ą┐ą╗ąĄą║čüąŠą▓, čéą░ą║ ą║ą░ą║ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĖčéčī ą▓ąĘą░ąĖą╝ąŠąĖčüą║ą╗čÄčćą░čÄčēąĖą╝ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąĖčģ ąĖ čéčĆą░ąĮąĘą░ą║čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝ ą┐čĆąĖ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĖ čäąĖąĘąĖč湥čüą║ąĖčģ ąæąö.
ąÆ ą┤ą░ąĮąĮąŠą╝ čüą╗čāčćą░ąĄ čüąĖčüč鹥ą╝ą░ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ, ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ čÅą▓ą╗čÅąĄčéčüčÅ čåąĄąĮčéčĆąŠą╝, ą▓ąŠą║čĆčāą│ ą║ąŠč鹊čĆąŠą│ąŠ čüčéčĆąŠąĖčéčüčÅ ą▓čüčÅ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąÜąźąö. ąśąĮč乊čĆą╝ą░čåąĖčÅ ąĖąĘ čĆą░ąĘąĮąŠčĆąŠą┤ąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą┐ąŠčüčéčāą┐ą░ąĄčé ą▓ ETL, ą║ąŠč鹊čĆą░čÅ ąĘą░ą│čĆčāąČą░ąĄčé ąŠčćąĖčēąĄąĮąĮčŗąĄ ąĖ čüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ ą”ąźąö, ą▓ ąŠą┐ąĄčĆą░čéąĖą▓ąĮčŗą╣ čüą║ą╗ą░ą┤ ą┤ą░ąĮąĮčŗčģ (ą×ąĪąö), ąĄčüą╗ąĖ ąŠąĮ ąĄčüčéčī (čüą╝. čĆąĖčü. 4). ąØąŠ ąĘą░ą│čĆčāąĘą║ą░ ą┤ą░ąĮąĮčŗčģ ą▓ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĖąĘ ETL ąĮą░ą┐čĆčÅą╝čāčÄ.
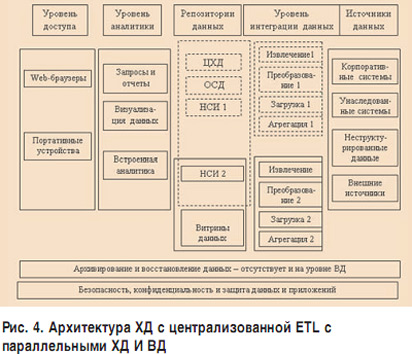
ąØą░ ą┐čĆą░ą║čéąĖą║ąĄ čéą░ą║ą░čÅ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĖąĘ-ąĘą░ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ čüą║ąŠčĆąĄą╣čłąĄą│ąŠ, ą▒ąĄąĘ ą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąĘą░ą┤ąĄčƹȹĄą║, ą┤ąŠčüčéčāą┐ą░ ą║ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąĖą╝ ą┤ą░ąĮąĮčŗą╝. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą│ąŠ čüą║ą╗ą░ą┤ą░ ą┤ą░ąĮąĮčŗčģ ąĮąĄ čĆąĄčłą░ąĄčé ąĘą░ą┤ą░čćąĖ, čéą░ą║ ą║ą░ą║ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ą┤čĆčāą│ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ, ąĖ ąĖą╝ čéčĆąĄą▒čāąĄčéčüčÅ č鹥čĆčĆąĖč鹊čĆąĖą░ą╗čīąĮą░čÅ ą▓ąĖčéčĆąĖąĮą░ ą┤ą░ąĮąĮčŗčģ. ąöčĆčāą│ąŠą╣ ą┐čĆąĖčćąĖąĮąŠą╣ ą╝ąŠąČąĄčé čüčéą░čéčī ąĘą░ą┐čĆąĄčé ąĮą░ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ čĆą░ąĘąĮąŠčéąĖą┐ąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą▓ ą×ąĪąö ą┐ąŠ čüąŠąŠą▒čĆą░ąČąĄąĮąĖčÅą╝ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ.
ą¤ąŠ č鹥ą╝ ąĖą╗ąĖ ąĖąĮčŗą╝ ą┐čĆąĖčćąĖąĮą░ą╝ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ą▓čüčéčĆąĄčćą░čÄčéčüčÅ, ąĖ ąŠą┤ąĮąŠą╣ ąĖąĘ ą┐čĆąŠą▒ą╗ąĄą╝ ąĖčģ 菹║čüą┐ą╗čāą░čéą░čåąĖąĖ čÅą▓ą╗čÅčÄčéčüčÅ čüą╗ąŠąČąĮąŠčüčéąĖ čü ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ ą┐ąŠčüą╗ąĄ ą║čĆą░čģą░ ą▓ąĖčéčĆąĖąĮ, ąĮą░ą┐čĆčÅą╝čāčÄ čüąĮą░ą▒ąČą░čÄčēąĖčģčüčÅ ąĖąĘ ETL. ąöąĄą╗ąŠ ą▓ č鹊ą╝, čćč鹊 čüčĆąĄą┤čüčéą▓ą░ ETL ąĮąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮčŗ ą┤ą╗čÅ ą┤ąŠą╗ą│ąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ čģčĆą░ąĮąĄąĮąĖčÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĮčŗčģ ąĖ ąŠčćąĖčēąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąóčĆą░ąĮąĘą░ą║čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, ąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░ąĮčŗ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ č鹥ą║čāčēąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣. ą¤ąŠčŹč鹊ą╝čā ą┐čĆąĖ ą┐ąŠč鹥čĆąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą▓ąĖčéčĆąĖąĮą░čģ, čüą▓čÅąĘą░ąĮąĮčŗčģ čü ETL, ą┐čĆąĖčģąŠą┤ąĖčéčüčÅ ą╗ąĖą▒ąŠ ą┐ąŠą┤ąĮąĖą╝ą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąĖąĘ čüčĆąĄą┤čüčéą▓ čĆąĄąĘąĄčĆą▓ąĮąŠą│ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝, ą╗ąĖą▒ąŠ ąŠčĆą│ą░ąĮąĖąĘąŠą▓čŗą▓ą░čéčī ąĖčüč鹊čĆąĖč湥čüą║ąĖąĄ ą░čĆčģąĖą▓čŗ čüąĖčüč鹥ą╝ ŌĆō ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ.
ąĢčēąĄ ąŠą┤ąĮąĖą╝ čĆąĄčłąĄąĮąĖąĄą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą┤ą▓ąŠą╣ąĮąŠąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ą┐ąŠą┤ąŠą▒ąĮčŗčģ ą▓ąĖčéčĆąĖąĮ ŌĆō ąĮą░ą┐čĆčÅą╝čāčÄ ą║ čüčĆąĄą┤čüčéą▓ą░ą╝ ETL ąĖ ą║ ąźąö, čćč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĮąĄą┤ąŠčĆą░ąĘčāą╝ąĄąĮąĖčÅą╝ ąĖ ąĮąĄčüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĮąŠčüčéąĖ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąĖčģ čĆą░ą▒ąŠčé. ą¤čĆąĖčćąĖąĮą░ ą║čĆąŠąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ą┤ą░ąĮąĮčŗąĄ, ą┐ąŠčüčéčāą┐ą░čÄčēąĖąĄ ą▓ čģčĆą░ąĮąĖą╗ąĖčēąĄ, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, ą┐čĆąŠčģąŠą┤čÅčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĮą░ ąĮąĄą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖą▓ąŠčüčéčī čü čāąČąĄ ąĘą░ą│čĆčāąČąĄąĮąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą╝ąŠąČąĄčé ą┐čĆąĖą╣čéąĖ čäąĖąĮą░ąĮčüąŠą▓čŗą╣ ą┤ąŠą║čāą╝ąĄąĮčé čü čĆąĄą║ą▓ąĖąĘąĖčéą░ą╝ąĖ, ą┐ąŠčćčéąĖ čüąŠą▓ą┐ą░ą┤ą░čÄčēąĖą╝ąĖ čü ą┤ąŠą║čāą╝ąĄąĮč鹊ą╝, ą┐ąŠčüčéčāą┐ąĖą▓čłąĖą╝ ą▓ ą”ąźąö čĆą░ąĮąĄąĄ. ąĪąĖčüč鹥ą╝ą░ ETL, ąĮąĄ ąŠą▒ą╗ą░ą┤ą░čÅ ą┐ą░ą╝čÅčéčīčÄ ąŠą▒ąŠ ą▓čüąĄčģ ąĘą░ą│čĆčāąČąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, ąĮąĄ ą╝ąŠąČąĄčé ą▓čŗčÅą▓ąĖčéčī, čÅą▓ą╗čÅąĄčéčüčÅ ąĮąŠą▓čŗą╣ ą┤ąŠą║čāą╝ąĄąĮčé ąĘą░ą║ąŠąĮąĮčŗą╝ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ čüčāčēąĄčüčéą▓čāčÄčēąĄą│ąŠ ąĖą╗ąĖ čŹč鹊 ąŠčłąĖą▒ą║ą░.
ąĪčĆąĄą┤čüčéą▓ą░ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▓čŗčÅą▓ąĖčéčī ą┐ąŠą┤ąŠą▒ąĮčŗąĄ čüąĖčéčāą░čåąĖąĖ, ą┤ąĄą╣čüčéą▓čāčÅ ą▓ąĮčāčéčĆąĖ ąźąö. ąÆ čüą╗čāčćą░ąĄ ą▓čŗčÅą▓ą╗ąĄąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ąĮąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ąŠčéą▒čĆąŠčłąĄąĮčŗ. ąĢčüą╗ąĖ ąČąĄ čŹč鹊 čĆąĄą│ą╗ą░ą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ, č鹊 ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą║ąŠčüąĮčāčéčüčÅ ąĮąĄ č鹊ą╗čīą║ąŠ ą┤ą░ąĮąĮčŗčģ čåąĖčäčĆ, ąĮąŠ ąĖ ą░ą│čĆąĄą│ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┐ąŠą║ą░ąĘą░č鹥ą╗ąĄą╣, čüąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗčģ ą┐čĆąĖ čāčćą░čüčéąĖąĖ ąĖčüą┐čĆą░ą▓ą╗čÅąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĖąĮč乊čĆą╝ą░čåąĖčÅ, ą┐ąŠą┐ą░ą▓čłą░čÅ ą▓ ą▓ąĖčéčĆąĖąĮčā ą┤ą░ąĮąĮčŗčģ ąĮą░ą┐čĆčÅą╝čāčÄ ąĖąĘ ETL, ą╝ąŠąČąĄčé ą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖčéčī ą┤ą░ąĮąĮčŗą╝, ą┐ąŠčüčéčāą┐ąĖą▓čłąĖą╝ ąĖąĘ ą”ąźąö. ąÆ ą║ą░č湥čüčéą▓ąĄ čĆąĄčłąĄąĮąĖčÅ ąĖąĮąŠą│ą┤ą░ ą▓ ą▓ąĖčéčĆąĖąĮąĄ čĆąĄą░ą╗ąĖąĘčāčÄčé č鹥 ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┤ą░ąĮąĮčŗčģ, čćč鹊 ąĖ ą▓ ą”ąźąö. ąØąĄą┤ąŠčüčéą░čéą║ąŠą╝ čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąŠą┤ąĮąĖčģ ąĖ č鹥čģ ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ą▓ ą”ąźąö ąĖ ą▓ ą▓ąĖčéčĆąĖąĮą░čģ, ą┐ąĖčéą░čÄčēąĖčģčüčÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ąŠčé ETL.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ą┐ąŠą▓č鹊čĆąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┤ą░ąĮąĮčŗčģ, ą║ čüąŠąĘą┤ą░ąĮąĖčÄ ąĖąĘą▒čŗč鹊čćąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ ą░čĆčģąĖą▓ąŠą▓, ą║ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĄ ą┤čāą▒ą╗ąĖčĆčāčÄčēąĖčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ąĖ ą┤ąĄčåąĄąĮčéčĆą░ą╗ąĖąĘą░čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ, čćč鹊, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, čÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąĖčćąĖąĮąŠą╣ ąĮąĄčüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĮąŠčüčéąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ.
ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗąĄ ą▓ąĖčéčĆąĖąĮčŗ ąĖą╝ąĄčÄčé ą┐čĆą░ą▓ąŠ ąĮą░ čüčāčēąĄčüčéą▓ąŠą▓ą░ąĮąĖąĄ ą▓ č鹥čģ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą║ ą░ąĮą░ą╗ąĖčéąĖč湥čüą║ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą▓ą░ąČąĮąĄąĄ ąĮąĄą┤ąŠčüčéą░čéą║ąŠą▓ čŹč鹊ą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ.
ą×ą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ: ą¢čāčĆąĮą░ą╗ "ąóąĄčģąĮąŠą╗ąŠą│ąĖąĖ ąĖ čüčĆąĄą┤čüčéą▓ą░ čüą▓čÅąĘąĖ" #4, 2011
ą¤ąŠčüąĄčēąĄąĮąĖą╣: 27208
ąĪčéą░čéčīąĖ ą┐ąŠ č鹥ą╝ąĄ
ąÉą▓č鹊čĆ
| |||
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣


