
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
Павел Зернов
Аспирант СПб ГУТ им. Бонч-Бруевича

Снижение требований к каналу связи и повышение крипто-устойчивости всегда являются актуальной задачей при передаче речи. Современные подходы базируются на использовании системы сжатия голоса и шифрования. Но какие бы новые кодеки ни разрабатывались, все они основываются на сжатии путем ухудшения качества речи, при этом всегда существует предел, ниже которого сжатие невозможно. Нужен новый подход, при котором качество речи не ухудшается, а трафик, передаваемый по каналу связи, значительно уменьшается. Для применения существующих математических методов в системе шифрования необходимо иметь входные данные, представленные последовательностью чисел.
Для решения поставленной задачи предлагается использование нового принципа формирования текстовых сообщений для системы экспресс-сообщений описанного ранее [1].
Требования к системе распознавания речи: работа в реальном масштабе времени, низкий процент ошибок распознавания слов, словарь, достаточный для распознавания слов, используемых в общих разговорах. Дополнительные требования: работа с различными языками, модульность, независимость от операционной системы и вычислительного устройства, система с открытым кодом и открытой лицензией.
 Требования к системе экспресс-сообщений: оптимизация передаваемого трафика за счет сведения к минимуму служебной информации в передаваемых пакетах, работа на базе протокола TCP/IP, система с открытым кодом и
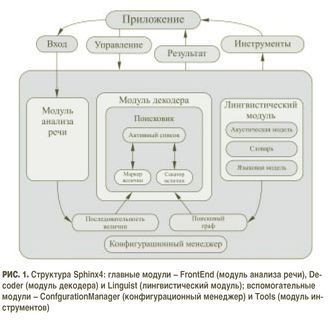
открытой лицензией. Исходя из этих требований была выбрана система распознавания Sphinx 4 [2], структура которой разработана с высокой степенью масштабируемости и модульности (рис. 1). Каждый элемент представляет модуль, который может быть легко заменен, разрешая тем самым проводить различные эксперименты.
Требования к системе экспресс-сообщений: оптимизация передаваемого трафика за счет сведения к минимуму служебной информации в передаваемых пакетах, работа на базе протокола TCP/IP, система с открытым кодом и
открытой лицензией. Исходя из этих требований была выбрана система распознавания Sphinx 4 [2], структура которой разработана с высокой степенью масштабируемости и модульности (рис. 1). Каждый элемент представляет модуль, который может быть легко заменен, разрешая тем самым проводить различные эксперименты.
В качестве системы экспресс-сообщений заданным требованиям отвечает система, построенная на протоколе ХМРР [8]. Базовые технологии ХМРР обычно осуществляются посредством стандартной клиент-серверной архитектуры (очень схожей с электронной почтой), когда клиент соединяется с сервером через TCP-гнез-до (socket), а затем организует XML-поток. Протокол XMPP определяет использование только TCP-протоко-ла, включающего в себя контроль нагрузки сети и являющегося более управляемым и безопасным для администрирования. В нем нет ограничений на количество передаваемых байт.
На основе выбранных систем был проведен первый эксперимент, в ходе которого на компьютере одного пользователя производилось распознавание произнесенной речи, представленной в виде предложений, а затем ее передача в виде текста на компьютер другого пользователя на базе системы экспресс-сообщений по протоколу ХМРР через Интернет.
Эксперимент проводился с различными значениями параметра relati-veBeamWidth в модуле декодера на одной и той же конфигурации компьютера пользователя-отправителя сообщений Intel Core 2 Duo E6550 2,33 ГГц, 2 Гбайт ОЗУ. Параметр rela-tiveBeamWidth устанавливает минимальную величину относительно максимальной величины (maximumScore) в так называемом списке для удаления. Распознанные знаки со значениями, меньшими, чем произведение rela-tiveBeamWidth и maximumScore, будут удалены из списка. Параметр должен быть как можно меньше (около 0), иначе распознавание не работает. Чрезмерно маленькое значение приводит к увеличению времени распознавания. В ходе эксперимента производился подсчет количества отправленных байт информации через сетевой интерфейс компьютера, посылающего сообщения (табл. 1).
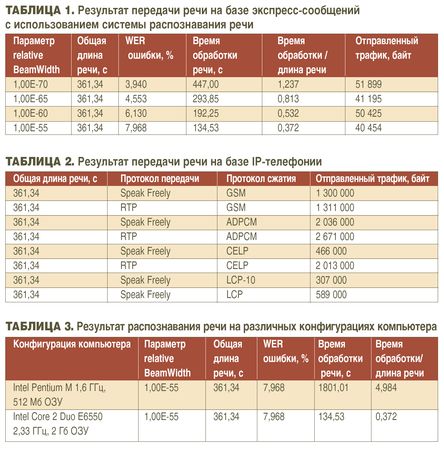 В ходе второго эксперимента была проведена передача речи, использованной в первом эксперименте, на базе системы IP телефонии с применением различных протоколов передачи и сжатия данных от одного пользователя к другому через Интернет. Эксперимент проводился на одной и той же конфигурации компьютера пользователя-отправителя речи Intel Core 2 Duo E6550 2,33 ГГц, 2 Гбайт ОЗУ. В ходе эксперимента производился подсчет количества отправленных байт информации через сетевой интерфейс компьютера, посылающего речь (табл. 2).
В ходе второго эксперимента была проведена передача речи, использованной в первом эксперименте, на базе системы IP телефонии с применением различных протоколов передачи и сжатия данных от одного пользователя к другому через Интернет. Эксперимент проводился на одной и той же конфигурации компьютера пользователя-отправителя речи Intel Core 2 Duo E6550 2,33 ГГц, 2 Гбайт ОЗУ. В ходе эксперимента производился подсчет количества отправленных байт информации через сетевой интерфейс компьютера, посылающего речь (табл. 2).
В ходе третьего эксперимента на различных конфигурациях компьютеров проводилось распознавание используемой ранее речи. Параметр rela-tiveBeamWidth был жестко задан для модуля декодера. Цель эксперимента -определение времени, затраченного на распознавание (табл. 3).
Сравнивая данные табл. 1 и 2, можно заметить, что значение передаваемого трафика при максимальном сжатии речи - табл. 2 (протокол сжатия LCP-10), равное 307 000 байт, и среднее значение из табл. 1, равное 45 993,25 байт, отличаются в 6,7 раза.
Таким образом, использование систем распознавания речи и передачи экспресс-сообщений на базе протокола XMPP дает существенную экономию трафика по сравнению с системами IP-телефонии. Эксперименты показали, что на сегодняшний день существует возможность распознавания речи в реальном масштабе времени с приемлемым процентом ошибок, при этом производительность процесса распознавания напрямую зависит от мощности вычислительного средства (табл. 3). Дальнейшее направление работ целесообразно вести в области улучшения качества распознавания речи за счет построения новой акустической модели русского языка, формирования законченной общей грамматики языка и точной настройки модулей декодирования и анализа речи. Кроме того, необходимо уделить внимание синтезу речи на принимающей стороне.
Литература
Опубликовано: Журнал "Технологии и средства связи" #2, 2008
Посещений: 6932
Статьи по теме
Автор
| |||
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
