
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
Павел Зернов
аспирант С.-Пб. ГУТ им. Бонч-Бруевича

На сегодняшний день практически все системы экспресс-сообщений позволяют совместно с текстовыми сообщениями передавать и голос. Классификация систем экспресс-сообщений по способу организации канала передачи речи представлена на рис 1.
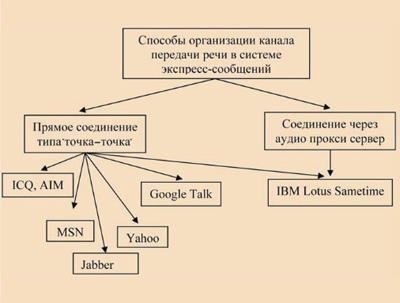
Рис. 1. Классификация систем экспресс-сообщений по способу организации канала передачи речи
В большинстве систем экспресс-сообщений передача речи
возможна только при прямом соединении "точка–точка" между клиентами.
На рис. 1, слева показаны системы, относящиеся к этой группе: ICQ, AIM
(протокол OSCAR), MSN (протокол MSNP), Yahoo (протокол YMSG), Google Talk
(протокол XMPP), Jabber (протокол XMPP). Система экспресс-сообщений IBM Lotus
Sametime (на рис. 1 справа), работающая по протоколу SIMPLE, поддерживает как
прямое соединение, так и соединение через аудиопрокси-сервер при организации
канала передачи речи.
Рассматриваемые системы экспресс-сообщений работают в
пакетных сетях, в основе которых лежит IP-протокол, определяющий два
транспортных механизма – протокол пользовательских дейтаграмм UDP и протокол
управления передачей TCP. Как правило, когда необходимо надежное соединение,
имеет смысл использовать протокол TCP, если необходима простота, но
необязательна надежность – протокол UDP.
В связи с чувствительностью к реальному времени голосового
трафика для передачи голоса логично выбрать протокол UDP/IP. Однако передача
пакет за пакетом, характерная для протокола UDP, обеспечивает недостаточно
подробную информацию для передачи голоса на базе IP. Например, Internet
Engineering Task Force для передачи в реальном масштабе времени трафика,
чувствительного к задержке, выбрала протокол RTP (Real-Time Transport
Protocol). Голосовые данные системы экспресс-сообщений передаются поверх
протокола RTP, который, в свою очередь, передается поверх протокола UDP.
Следовательно, пакет передается с заголовком RTP/UDP/IP.
Вне зависимости от протокола прикладного уровня, все системы
экспресс-сообщений для передачи речи используют протокол RTP. Он предоставляет
принимающей станции информацию, отсутствующую в не требующих установления
соединения потоках UDP/IP. Два важнейших бита информации в заголовке RTP-пакета
– порядковый номер (sequence number) и временная метка (timestamp). Протокол
RTP использует информацию о последовательности пакетов, чтобы определить, по
порядку ли они прибывают, а информация о временных метках нужна для определения
времени доставки пакета от отправителя до получателя. При необходимости этот
протокол можно использовать как для передачи мультимедийных данных, так и для
интерактивных служб телефонии Интернета. Протокол RTP имеет две составляющие –
часть данных (data part) и часть контроля (control part).
Установление и разрыв соединения не входят в список
возможностей RTP, такие действия выполняются сигнальным протоколом (например,
протоколом SIP).
Протокол RTP обладает рядом недостатков. Заголовки IP/RTP/UDP
составляют 20, 8 и 12 байт соответственно. В целом получается уже 40-байтовый
заголовок, который вдвое больше, чем полезная нагрузка при использовании G.729
с двумя голосовыми выборками (20 мс). RTP не имеет стандартного
зарезервированного номера порта. Единственное ограничение состоит в том, что
соединение проходит с использованием четного номера, а следующий нечетный номер
используется для связи по протоколу RTCP. Тот факт, что RTP работает с
динамически назначаемыми адресами портов, создает ему трудности для прохождения
межсетевых экранов. Для обхода этой проблемы, как правило, применяют
STUN-сервер.
Для уменьшения объема передаваемых в канал данных
применяются методы сжатия речевого сигнала, основанные на различных принципах
кодирования. Для этого используются кодеки, обеспечивающие преобразование
речевого сигнала.
РСМ и ADPCM – это примеры кодеков аналогово-цифрового
преобразования, их методы сжатия эксплуатируют непосредственно избыточные
характеристики аналогового сигнала. Новые методы сжатия, использующие знания
фундаментальных характеристик создания голосовых данных, были разработаны 10–15
лет назад. В этих методах применены процедуры обработки сигнала, которые
сжимают голосовые данные, отправляя упрощенную параметрическую информацию
относительно исходных данных. Для передачи этой информации требуется меньшая
пропускная способность. Эти методы, как правило, объединены в исходные кодеки,
включающие такие варианты, как кодирование методом линейного предсказания
(Linear Predictive Coding – LPC), алгоритм сжатия при кодировании методом
линейного предсказания (Code Excited Linear Prediction Compression – CELP) и
мультиимпульсное многоуровневое квантование (Multipulse, Multilevel
Quantization – MP-MLQ). Схемы кодирования CELP, MP-MLQ РСМ и ADPCM
стандартизированы ITU-T в рекомендациях серии G.
Вторая причина задержки – фактическая задержка очереди
вывода. Этот фактор следует учитывать при использовании любых методов
формирования очереди для сети, оптимальным является значение меньше 10 мс.
В неуправляемой переполненной сети задержка очереди может
дополнительно возрасти почти до двух секунд (потеря пакетов тоже не исключена).
Задержка такой продолжительности недопустима практически во всех голосовых
сетях. Однако это всего лишь один из компонентов сквозной задержки. Другой
способ ее проявления – это дребезг, иными словами, неравномерность периодов
времени на доставку пакетов. Дребезг относится как раз к тем проблемам, которые
существуют только в пакетных сетях. Отправитель ожидает, что голосовые пакеты
будут передаваться с одинаковыми интервалами. Эти голосовые пакеты могут
задержаться в сети и не достичь принимающей станции за обычный интервал.
Разница во времени между тем, когда ожидалось получение пакета, и временем
фактического получения и есть дребезг.
У рассмотренного выше способа передачи речи на базе системы
экспресс-сообщений существует несколько недостатков. Во-первых, основанная на
протоколе RTP передача речи, в рамках систем экспресс-сообщений, несет в себе
ряд проблем. Необходимость прямого соединения между пользователями для передачи
речевых данных создает проблемы при прохождении межсетевых экранов и систем
трансляции адресов (NAT). В этом случае невозможны многопользовательские конференции.
Дополнительные проблемы с межсетевыми экранами вносит факт динамической
генерации номера порта RTP. Большой размер заголовка RTP-пакета по сравнению с
объемом передаваемых полезных данных снижает эффективность передачи речевых
данных и повышает нагрузку на сеть.
Во-вторых, все используемые в системах экспресс-сообщений
кодеки основываются на методе сжатия данных с потерями. Преимущество методов
сжатия с потерями над методами сжатия без потерь состоит в том, что первые
существенно превосходят по степени сжатия, продолжая удовлетворять поставленным
требованиям. Но какие бы новые кодеки ни разрабатывались, всегда существует
предел, ниже которого сжатие невозможно.
В-третьих, высокая нагрузка на сеть за счет большой
интенсивности передачи данных, так как очередной голосовой пакет передается в
канал через каждые 20 мс. Это приводит к возникновению задержек в доставке
пакетов и к дребезгу.
Нужен новый подход, при котором качество речи не ухудшилось
бы, при этом значительно снизился бы
передаваемый в канал трафик и существовала бы возможность
многопользовательского голосового общения на базе основного протокола
функционирования системы экспресс-сообщений.
Основной идеей предлагаемого нового подхода является
использование на клиентских станциях системы экспресс-сообщений распознавания и
синтеза речи с кодированием сообщений при передаче по словарю.
Развитие элементной базы современных персональных
компьютеров и доступность компонентов (ОЗУ, ПЗУ, ЦП) позволяет производить
большую часть вычислений средствами клиентского программного обеспечения
системы экспресс-сообщений, снижая тем самым избыточность речевого сигнала.
Основываясь на специфике экспресс-сообщений, позволяющей определить языковой
словарь клиентов и построить лингвистическую модель их общения, целесообразно
для удаления из речевого сигнала акустической составляющей использование
системы распознавания речи, созданной на базе словаря системы
экспресс-сообщений. В предлагаемой системе клиентское программное обеспечение
производит преобразование поступающей через микрофон речи в текстовые сообщения
в реальном масштабе времени. Текстовые сообщения также обладают определенной
степенью избыточности, которая может быть сокращена преобразованием сообщений в
коды на основе словаря. При этом в канал связи поступают только числовые
последовательности, инкапсулируемые в пакеты протокола системы
экспресс-сообщений (XMPP, SIMPLE, OSCAR и т.д.). Вследствие использования для
передачи речи основного протокола нет необходимости прямого соединения между
пользователями системы экспресс-сообщений. Это дает возможность создания
многопользовательских конференций и упрощает прохождение межсетевых экранов и
систем трансляции адресов. Доставленные получателю сообщения преобразуются
клиентским программным обеспечением из числовых последовательностей в текстовые
и передаются в систему синтеза речи. Для снижения задержек синтеза система
размещена на выделенном компьютере в локальной сети клиента системы
экспресс-сообщений. Отправленное на сервер синтеза текстовое сообщение с помощью
словаря экспресс-сообщений синтезируется в речевое и перенаправляется
получателю, где воспроизводится через динамик.
Предложенный подход может обеспечить передачу речи в системе экспресс-сообщений в реальном масштабе времени. При этом появляется возможность значительного снижения объема передаваемого трафика и уменьшения нагрузки на сеть.
Опубликовано: Журнал "Технологии и средства связи" #5, 2008
Посещений: 10739
Статьи по теме
Автор
| |||
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций

