
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций
Павел Зернов
Аспирант СПб ГУТ им. Бонч-Бруевича

Зкспресс-сообщения - очень удобный способ обмена информацией. Во-первых, сообщения отправляются мгновенно, поэтому можно общаться в реальном времени. Во-вторых, отправитель всегда знает, в каком состоянии находится его собеседник, а именно: готов поговорить, отошел или вообще не доступен. Однако, при всех своих достоинствах, экспресс-сообщения имеют существенный недостаток - необходимо вводить текст на клавиатуре, что снижает скорость общения и утомляет собеседников. Кроме того, входящие сообщения приходится читать на дисплее компьютера, КПК или мобильного телефона, что тоже неудобно. В основном через систему экспресс-сообщений общаются люди, имеющие общие интересы и говорящие на одном языке, что дает возможность определить языковой словарь этой группы людей. Следовательно, для упрощения общения целесообразно использовать системы распознавания и синтеза речи для ввода и воспроизведения отправляемого и полученного текста. Новый подход к формированию текстовых сообщений описан ранее [1], доказана возможность распознавания слов в реальном масштабе времени [2], поэтому для обоснования возможности передачи речи на базе экспресс-сообщений необходимо исследовать процесс синтеза русской речи. Если технически окажется возможным воспроизводить речь в реальном масштабе времени с приемлемым качеством, то на базе экспресс-сообщений можно будет передавать речь, существенно экономя трафик или используя при передаче узкие каналы связи. Кроме того, синтез речи может быть использован в информационно-справочных системах с целью оказания помощи людям с ограниченными возможностями, для выдачи информации о технологических процессах, в военной и космической технике, в робототехнике, а также в акустическом диалоге человека с компьютером.
Определим базовые требования к синтезу речи при его использовании в системе экспресс-сообщений:
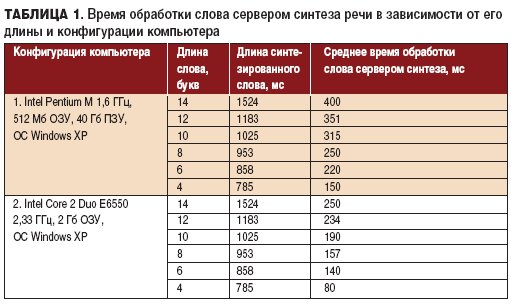
На сегодняшний момент существуют несколько наиболее известных систем синтеза речи с открытым кодом: FreeTTS, OpenMary, Festival. Для эксперимента была выбрана программа Festival, поскольку для нее существуют базы русского языка. Система написана на языке C++, использует Эдинбургскую библиотеку речевых инструментов (Edinburgh Speech Tools) на системном уровне, имеет собственный интерпретатор команд управления SIOD и может работать в клиент-серверной архитектуре. Целью эксперимента было определение времени задержки (в зависимости от конфигурации компьютера и длины слова) перед воспроизведением синтезированного сообщения. С использованием API системы Festival на языке Java была написана программа, позволяющая в автоматическом режиме передавать из заранее подготовленного массива слов, через открытое сетевое гнездо (socket), отдельные слова на сервер синтеза речи Festival, работающий на том же компьютере, где и клиент. В ответ на каждое отправление сервер возвращал результат синтеза -звуковой wav файл. Время, прошедшее с момента отправки слова до момента получения звукового файла, фиксировалось в специальном журнале. В итоге эксперимента удалось получить статистику задержек при синтезе слов различной длины, приведенную (табл. 1).
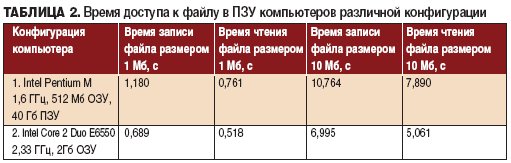
Синтез речи осуществлялся кластерным способом, поэтому на первом плане оказалась не производительность процессора, а время доступа к речевым базам, находящимся в ПЗУ. Для определения времени доступа к файлам в ПЗУ был проведен второй эксперимент. В ходе эксперимента замерялось время записи и чтения маленького файла (размер 1 Мб) и большого файла (10 Мб) на разных конфигурациях компьютеров. Результаты приведены в табл. 2.
В телефонии предполагается, что для комфортного разговора между абонентами в сети необходимо обеспечить задержку прохождения голосового сигнала не более чем 250 мс. В табл. 3 приведены требования стандарта ISO 9000 к передаче телефонного трафика по технологии VoIP.

Из табл. 1 видно, что время обработки слова напрямую зависит от его длины, но оно в несколько раз меньше длины синтезированного слова. В итоге, с учетом задержек при распознавании и передачи речи, суммарное время доставки произнесенного слова, скорее всего, превысит время, допустимое для лучшего и высокого классов обслуживания в соответствии с требованиями ISO 9000. С другой стороны, на основе данных табл. 1 и табл. 2 можно сделать вывод, что использование ПЗУ с меньшим временем доступа уменьшает задержку в синтезе слов. Анализируя процесс распознавания речи в реальном времени [2], можно заметить, что при увеличении быстродействия процессора время распознавания слов уменьшается.
Основываясь на результатах эксперимента для моделирования синтеза речи в системе экспресс-сообщений Jabber, был создан демо-стенд, схема которого приведена на рис. 1.
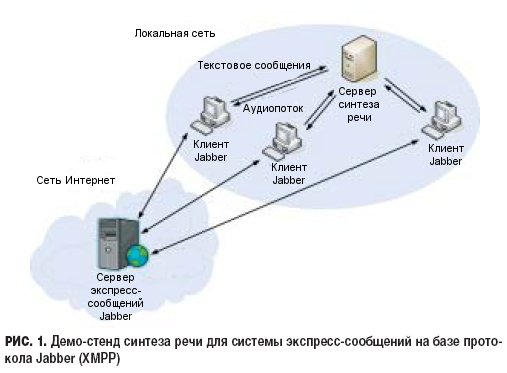
Стенд представлял собой сервер синтеза речи на базе программы Festival, работающий под управлением операционной системы FreeBSD 7.0 и три рабочие станции (Windows XP) -клиенты системы экспресс-сообщений. В конфигурации сервера использовался процессор Intel Core 2 Duo Е6550, 2 Гб ОЗУ; в качестве ПЗУ, где хранилась файловая система, использовалась USB флэш-карта объемом 4 Гб. Для ускорения обработки сообщений, файловая партиция для каталога tmp размером 500 Мб, в котором сохранялись промежуточные вычисления, была смонтирована в памяти. Принцип работы стенда состоял в том, что полученные клиентами текстовые сообщения переправлялись на сервер FreeBSD, где синтезировались в звуковые файлы и возвращались обратно в виде бинарных аудиопотоков. Получив аудиопоток, клиентское программное обеспечение воспроизводило его через звуковую карту. Воспроизводимые слова были понятны человеческому уху, но искажения, связанные с неправильной простановкой ударений в слове, иногда имели место. Таким образом, со стороны пользователей рабочих станций складывалось впечатление, что их собеседник для ответа использует речь, а не текст. В процессе эксперимента слова передавались как отдельно, так и в составе предложений, синтез же осуществлялся отдельно для каждого слова. Ответная речь собеседника приходила с задержкой, которая складывалась из времени, потраченного при наборе на клавиатуре компьютера ответа пользователем, и времени синтеза слова на сервере. Задержки, возникающие при синтезе слов разной размерности на сервере FreeBSD, представлены в табл. 4.
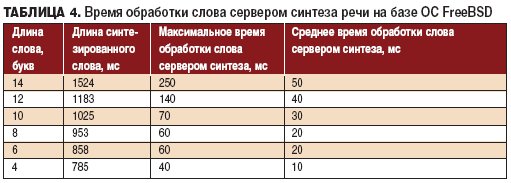
Использование выделенного сервера со специализированной операционной системой и перемещением части ПЗУ в ОЗУ уменьшило время синтеза слов до размера, соизмеримого с задержкой в 250 мс, требуемой в телефонии. Воспроизводимая речь была понятна человеку, несмотря на искажения в ударениях. Таким образом, можно сделать вывод о возможности использования системы синтеза речи для воспроизведения в реальном времени текста в системе экспресс-сообщений на существующей аппаратной базе, а также в остальных системах, где получателем информации является человек.
Литература.
Опубликовано: Журнал "Технологии и средства связи" #3, 2008
Посещений: 11071
Статьи по теме
Автор
| |||
В рубрику "Решения корпоративного класса" | К списку рубрик | К списку авторов | К списку публикаций