
В рубрику "Решения операторского класса" | К списку рубрик | К списку авторов | К списку публикаций
 Юрий Бутыльский
Юрий Бутыльский
 Павел Зернов
Павел Зернов
Внастоящее время наряду с телефонной сетью общего пользования (ТФОП) все шире и шире применяется технология голосовой телефонии VoIP на базе глобальной сети Интернет. Учитывая распространенность сети Интернет и протокола TCP/IP, применение VoIP в этом случае позволяет: во-первых, охватить большое количество пользователей, во-вторых, снизить, по сравнению с ТФОП (рассматриваются цифровые системы, так как сравнение технологий VoIP и аналоговой передачи данных не уместно), объем передаваемых в канал связи данных. В дальнейшем можно предположить, что, как только Интернет обеспечит доставку голоса с качеством, сравнимым с тем, что предоставляет телефонная связь, ТФОП может ощутить значительно усилившуюся конкуренцию со стороны технологии VoIP.
Одним из базовых принципов построения сетей TCP/IP является негарантированное обслуживание. Поэтому сейчас невозможно предсказать, как растущий VoIP-трафик реального времени повлияет на общую производительность сети. В настоящее время превышение имеющейся полосы пропускания магистральной сети таково, что обеспечивает приемлемое качество даже в условиях негарантированного обслуживания. Но какая бы большая полоса пропускания ни была предоставлена, обязательно будет достигнут ее предел. Поэтому с ростом числа пользователей услуги VoIP будет увеличиваться и объем передаваемых данных, что потребует применения новых методов сжатия.
Существующие алгоритмы сжатия речи подошли к своему пределу компрессии. Увеличение коэффициента сжатия приводит к потерям качества сигнала. Поэтому необходим новый подход. Один из возможных подходов в передаче голосовой информации по сети Интернет основан на использовании словарей на передающей и приемной сторонах [1, 2]. Наряду с достоинством, а именно сокращением объема данных, передаваемых в канал связи, его недостатком является потеря естественности синтезируемой речи, то есть схожести с голосом исходного диктора. Подход предполагает передачу только речи, музыку или шумы окружающей среды передать по каналу связи невозможно, что в зависимости от сферы применения является как достоинством, так и недостатком.
Для исправления выявленных недостатков подхода [1, 2] предлагается изображенная на рисунке (стр. 25) структурная модель процессов гибридной компрессии акустического сигнала, в основе которой лежат скрытые марковские модели (СММ).

Модель, объединяющая в себе приемную, передающую стороны и канал связи, состоит из блоков, описывающих определенные процессы обработки акустического сигнала в системе передачи данных. Термин "гибридная компрессия" применяется в названии модели потому, что ее структура объединяет как классические, так и новые методы сжатия акустического сигнала.
Блок анализа непрерывного входного сигнала производит разбиение входного сигнала на фрагменты, размер которых варьируется от размера слова до размера фонемы (слога) в слове, и выявляет тип каждого фрагмента, то есть идентифицирует его либо как речь, либо как звук. В зависимости от идентификации проанализированный фрагмент поступает на дальнейшую обработку разным процессам. Речевой сигнал поступает на вход двух параллельных процессов: процесса распознавания и процесса анализа характеристик. Первый процесс производит сопоставление фрагменту сигнала код слова из словаря. Для этого во время обработки формируется СММ фрагмента речевого сигнала, которая затем сравнивается с эталонными моделями из словаря. Процесс наиболее ресурсоемкий, но в зависимости от глубины СММ позволяет с высокой вероятностью правильно сопоставить фрагмент речи с кодом слова из словаря.
Анализ характеристик речевого сигнала позволяет выявить особенности речи диктора, которые в дальнейшем будут переданы на приемную сторону в виде математических матриц и использованы для синтеза исходной речи с учетом тембральных и психоэмоциональных особенностей голоса человека. Полученные таким образом коды слов или фонем инкапсулируются в кадры протокола TCP/IP в процессе формирования пакетов. Фрагменты входного сигнала, которые были идентифицированы как звуковой сигнал, попадают в кадры протокола TCP/IP в виде оцифрованных выборок спектра сигнала, то есть с использованием традиционного кодека. Такой подход позволяет обработать акустический сигнал в диапазоне 300–30 000 Гц без потерь его фрагментов.
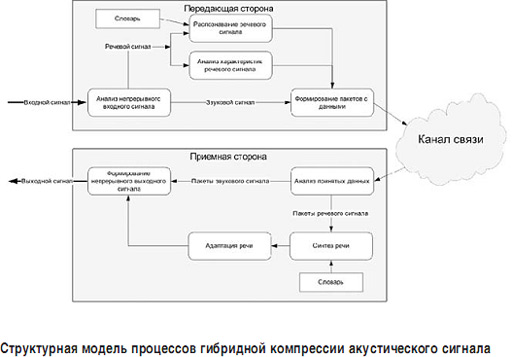
Сформированные пакеты передаются на приемную сторону по сети Интернет. На приемной стороне фрагменты, извлеченные из пакетов, идентифицируются в процессе анализа принятых данных и в зависимости от типа (звуковой сигнал или речь) либо синтезируются в речь, либо декодируются во фрагменты исходного сигнала. Синтез речи представляет собой процесс построения речевого сигнала длиной от слова до фонемы (слога) путем формирования СММ по коду полученного слова или фонемы. СММ с наивысшей вероятностной оценкой преобразуется в речь. Механизм адаптации позволяет добиться схожести синтезированного и исходного, произнесенного диктором фрагмента акустического сигнала. Процесс формирования непрерывного речевого сигнала собирает фрагменты речевого и звукового сигналов в единый выходной сигнал, который затем и воспроизводится на приемной стороне.
Выделим главные процессы, влияющие на идентичность входного (на передающей стороне) и выходного (на приемной стороне) акустического сигнала:
Предлагаемый новый подход, представленный в виде структурной модели, решающий проблему все возрастающего VoIP-трафика. Это снижение по сравнению с технологией VoIP объема данных, передаваемых в канал связи, за счет применения гибридной компрессии. При этом речь синтезируется с учетом тембральных и психоэмоциональных характеристик голоса диктора.
Для оценки целесообразности предложенного подхода необходимо провести моделирование процесса анализа непрерывного входного сигнала и выявить процентное соотношение звука и речи во входном акустическом сигнале на примере телефонного разговора абонентов ТФОП. Такая зависимость позволит спрогнозировать количественные оценки степени компрессии акустического сигнала, так как коэффициент сжатия классических кодеков известен, а порядок кодов распознанного слова или фонемы определяется размерами словаря. Моделирование процесса распознавания речи позволит выявить оптимальные размеры словаря и глубину СММ, а также выявит процент ошибок распознавания слов и фонем. Моделирование синтеза речи с адаптацией голоса позволит оценить качество синтезируемой речи по сравнению с исходным голосом диктора. Таким образом, в статье была описана проблема, предложено ее решение и сформулированы дальнейшие шаги по исследованию данной тематики.
Литература:
Опубликовано: Журнал "Технологии и средства связи" #1, 2011
Посещений: 6094
Статьи по теме
Автор
| |||
Автор
| |||
В рубрику "Решения операторского класса" | К списку рубрик | К списку авторов | К списку публикаций

