
ąÆ čĆčāą▒čĆąĖą║čā "ąÜąŠą╝ą┐ą╗ąĄą║čüąĮčŗąĄ čĆąĄčłąĄąĮąĖčÅ. ąśąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣

ąÜą░ą║ čāą┤ą░čćąĮąŠ ąĘą░ą╝ąĄčéąĖą╗ ą▓ čüą▓ąŠąĄą╣ ą┐ąĄčüąĮąĄ ąÉąĮą┤čĆąĄą╣ ą£ą░ą║ą░čĆąĄą▓ąĖčć: "ąĢčüą╗ąĖ čåąĄą╗čī ąŠą┤ąĮą░ ąĖ ą▓ čĆą░ą┤ąŠčüčéąĖ, ąĖ ą▓ ą│ąŠčĆąĄ, č鹊 č鹊čé, ą║č鹊 ąĮąĄ čüčéčĆčāčüąĖą╗ ąĖ ą▓ąĄčüąĄą╗ ąĮąĄ ą▒čĆąŠčüąĖą╗, č鹊čé ąĘąĄą╝ą╗čÄ čüą▓ąŠčÄ ąĮą░ą╣ą┤ąĄčé".
ąĀąĖčüą║ąĮčā ą┐ąŠą┤ąĮčÅčéčī ą▓ąŠą┐čĆąŠčü: ą░ ą▒čŗą▓ą░čÄčé ą╗ąĖ ą▓ ą┐čĆąĖąĮčåąĖą┐ąĄ ąĄą┤ąĖąĮčŗąĄ čåąĄą╗ąĖ čā čüąŠčéčĆčāą┤ąĮąĖą║ąŠą▓, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą┐ąŠ ą▓ąŠą╗ąĄ čĆčŗąĮą║ą░ ą▓ ą▒ąĖąĘąĮąĄčü-ą║ąŠą╝ą┐ą░ąĮąĖąĖ ąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖčģ čüąĄčĆą▓ąĖčüąĮčāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā? ąöčāą╝ą░čÄ, ą║ą░ąČą┤čŗą╣ ąĖąĘ ąĮą░čü ą┐ąĄčĆąĄąČąĖą▓ą░ąĄčé ą╗ąĄą│ą║ąŠąĄ ą▓ąŠą╗ąĮąĄąĮąĖąĄ, ąĘą▓ąŠąĮčÅ ą┐ąŠ č鹥ą╗ąĄč乊ąĮčā ą▓ ąŠč湥čĆąĄą┤ąĮąŠą╣ čüąĄčĆą▓ąĖčü-čåąĄąĮčéčĆ: "ąźąŠčéčī ą▒čŗ čéčĆčāą▒ą║čā čüąĮčÅą╗ ą▓ą╝ąĄąĮčÅąĄą╝čŗą╣ čüąŠčéčĆčāą┤ąĮąĖą║!"
ąæąĖąĘąĮąĄčü-ą┐čĆąŠčåąĄčüčü čģąŠčĆąŠčłąŠ čĆą░ą▒ąŠčéą░ąĄčé, ą║ąŠą│ą┤ą░:
ąÉ ąĄčüą╗ąĖ ąŠčéą║ą╗ąŠąĮąĄąĮąĖčÅ ąŠčé čüčåąĄąĮą░čĆąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤čÅčé? ąÉ ąĄčüą╗ąĖ ąŠąĮąĖ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ą┐ąŠč鹥čĆąĄ ą║ą░č湥čüčéą▓ą░? ąŚą░ą╝ąĄčćčā, čćč鹊 ąŠčéą║ą╗ąŠąĮąĄąĮąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą▓ čüą╗čāčćą░ąĄ ą▓ąĮąĄčłąĮąĄą│ąŠ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ą░ ą▓ čĆą░ą▒ąŠčéčā čüąĖčüč鹥ą╝čŗ ą╗ąĖą▒ąŠ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓ąĮąĄčüąĄąĮąĖčÅ ą▓ čüąĖčüč鹥ą╝čā ąĖąĘą╝ąĄąĮąĄąĮąĖą╣. ąóą░ą║ąĖąĄ čüąŠą▒čŗčéąĖčÅ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ ąĖąĮčåąĖą┤ąĄąĮčéą░ą╝ąĖ. ąśčģ čĆąĄčłą░čÄčé ą╗čÄą┤ąĖ, čĆą░ą▒ąŠčéą░čÄčēąĖąĄ ą┐ąŠ čüąĄčĆą▓ąĖčüąĮčŗą╝ ą┐čĆąŠčåąĄą┤čāčĆą░ą╝, ąĮąŠ ą▓čüąĄą│ą┤ą░ ąĖą╝ąĄčÄčēąĖąĄ čüą▓ąŠą▒ąŠą┤čā ą▓čŗą▒ąŠčĆą░, č湥ą╝ ąĖ ą║ą░ą║ ąĘą░ąĮąĖą╝ą░čéčīčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ. ąØąŠ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą┤čĆčāą│ąŠą╣ ą▓ąŠą┐čĆąŠčü: ą▓čüąĄą│ą┤ą░ ą╗ąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą╗čÄą┤ąĄą╣ čüąŠą▓ą┐ą░ą┤ą░čÄčé čü č鹥ą╝, čćč鹊 ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ą▒ąĖąĘąĮąĄčüą░ ą║ąŠą╝ą┐ą░ąĮąĖąĖ? ąÆąĄą┤čī ą║ąŠą│ą┤ą░ ą║ąŠčĆą░ą▒ą╗čī č鹊ąĮąĄčé, ą╝ąŠąČąĮąŠ ą▒ąĄąČą░čéčī ą┐ąŠą╝ąŠą│ą░čéčī ąĘą░ą┤ąĄą╗čŗą▓ą░čéčī ą┐čĆąŠą▒ąŠąĖąĮčā, ą░ ą╝ąŠąČąĮąŠ ą┐čĆąĖąĮčÅčéčī ą╝ąĄčĆčŗ ą┐ąŠ čāą┐ą╗ąŠčéąĮąĄąĮąĖčÄ ą┤ą▓ąĄčĆąĄą╣ čüą▓ąŠąĄą╣ ą║ą░čÄčéčŗ. ąóą░ą║ą░čÅ čüąĖčéčāą░čåąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ čüą▓ąŠą╣čüčéą▓ąŠą╝ ą╗čÄą▒ąŠą╣ ą║ąŠą╝ą┐ą░ąĮąĖąĖ.
ą¦č鹊 ąČąĄ ąĮą░ čŹčéčā č鹥ą╝čā ą│ą╗ą░čüčÅčé čüąĄčĆą▓ąĖčüąĮčŗąĄ ą╝ąĄč鹊ą┤ąŠą╗ąŠą│ąĖąĖ? ą£ąĄč鹊ą┤ąŠą╗ąŠą│ąĖąĖ ąŠčéą▓ąĄčćą░čÄčé ąĮą░ ą▓ąŠą┐čĆąŠčü: ą║čāą┤ą░ ąĖ ą║ą░ą║ ą▒čŗčüčéčĆąŠ ą▒ąĄąČą░čéčī, ąĄčüą╗ąĖ ą╝čŗ ąĘąĮą░ąĄą╝ ą┐čĆąĖąŠčĆąĖč鹥čé ąĖąĮčåąĖą┤ąĄąĮčéą░, ąŠą┤ąĮą░ą║ąŠ ąĮąĄ ąĘąĮą░ąĄą╝ ąŠčéą▓ąĄčéą░ ąĮą░ ą▓ąŠą┐čĆąŠčü: ą┐ąŠč湥ą╝čā čüąŠą▒čŗčéąĖąĄ ąĖą╝ąĄąĄčé ąĖą╝ąĄąĮąĮąŠ čéą░ą║ąŠą╣ ą┐čĆąĖąŠčĆąĖč鹥čé?
ąæąĄąĘčāčüą╗ąŠą▓ąĮąŠ, ą║ą░ąČą┤čŗą╣ čĆčāą║ąŠą▓ąŠą┤ąĖč鹥ą╗čī ą┐čŗčéą░ąĄčéčüčÅ ąĮą░ą▓ąĄčüčéąĖ ą┐ąŠčĆčÅą┤ąŠą║ ąĖ ą▓čŗčüčéčĆąŠąĖčéčī ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ą┐čĆąĖąŠčĆąĖč鹥čéčŗ. ąóą░ą║ąĖąĄ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┐čĆą░ą▓ąĖą╗ą░ ą▓čüąĄą│ą┤ą░ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░čÄčéčüčÅ ą╗ąŠąĘčāąĮą│ąŠą╝: "ąÆčüąĄ ą┤ą╗čÅ ą║ą╗ąĖąĄąĮčéą░", ąŠą┤ąĮą░ą║ąŠ čüąĖą╗čīąĮąŠ ąŠą│čĆą░ąĮąĖč湥ąĮčŗ ą┐čĆąĄą┤ą╝ąĄčéąĮąŠą╣ ąŠą▒ą╗ą░čüčéčīčÄ ą┐ąŠą┤čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ, ąĖąĮč鹥čĆą┐čĆąĄčéą░čåąĖąĄą╣ ąĖ ą╗ąĖčćąĮčŗą╝ąĖ čåąĄą╗čÅą╝ąĖ čüą░ą╝ąŠą│ąŠ čĆčāą║ąŠą▓ąŠą┤ąĖč鹥ą╗čÅ, ą┐ąŠčŹč鹊ą╝čā čüąŠąĘą┤ą░ąĮąĮčŗąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą▓ąŠą┤ąŠą▓ ą┐čĆą░ą▓ąĖą╗ ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▒čāą┤čāčé ą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖčéčī ą┤čĆčāą│ ą┤čĆčāą│čā. ą¤ąŠčģąŠąČąĄ, čćč鹊 ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čĆąĄčåąĄą┐čé - čŹč鹊 ą▓ąĮąĄą┤čĆąĄąĮąĖąĄ ąĄą┤ąĖąĮąŠą╣ čłą║ą░ą╗čŗ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą▓ąŠ ą▓čüąĄą╣ ą║ąŠą╝ą┐ą░ąĮąĖąĖ. ąĪąŠąĘą┤ą░ą▓ą░čÅ čéą░ą║čāčÄ čłą║ą░ą╗čā ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓, čü ąŠą┤ąĮąŠą╣ čüč鹊čĆąŠąĮčŗ, ąĮą░ą┤ąŠ ąŠč湥ąĮčī čģąŠčĆąŠčłąŠ ą┐ąŠąĮąĖą╝ą░čéčī čåąĄą╗ąĖ ą▒ąĖąĘąĮąĄčüą░, čü ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ąĮąĄ ą╝ąĄąĮąĄąĄ ą▓ą░ąČąĮąŠ ą┐ąŠąĮąĖą╝ą░čéčī čüčāą▒čŖąĄą║čéąĖą▓ąĮąŠčüčéčī ą┐čĆąĖčĆąŠą┤čŗ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ąĖ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ą▓ąĘą│ą╗čÅąĮčāčéčī ąĮą░ ąĮąĄą│ąŠ ąĮąĄ čüąŠ čüč鹊čĆąŠąĮčŗ ą▒ąĖąĘąĮąĄčüą░, ą░ čüąŠ čüč鹊čĆąŠąĮčŗ č湥ą╗ąŠą▓ąĄą║ą░.
ąśčéą░ą║, ą▓ čåąĄąĮčéčĆąĄ ą╗čÄą▒ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░, ą┤ą░ąČąĄ 菹╗ąĄą║čéčĆąŠąĮąĮąŠą│ąŠ, ąĮą░čģąŠą┤ąĖčéčüčÅ č湥ą╗ąŠą▓ąĄą║. ąÆ čüąŠąĘąĮą░ąĮąĖąĖ č湥ą╗ąŠą▓ąĄą║ą░ ą╝ąŠąČąĮąŠ čāčüą╗ąŠą▓ąĮąŠ ą▓čŗą┤ąĄą╗ąĖčéčī ą┤ą▓ą░ ą┐ąŠą╗čÄčüą░: ąĮąĖąČąĮąĖą╣ ą┐ąŠą╗čÄčü - ąĖąĮčüčéąĖąĮą║čé, ąŠą▒ą╗ą░čüčéčī ąĮą░ą║ąŠą┐ą╗ąĄąĮąĮąŠą│ąŠ čéčŗčüčÅč湥ą╗ąĄčéąĖčÅą╝ąĖ ąŠą┐čŗčéą░, ą│ą┤ąĄ ą╗čÄą▒ąŠąĄ ą▓ąĮąĄčłąĮąĄąĄ čüąŠą▒čŗčéąĖąĄ ą▓čŗąĘčŗą▓ą░ąĄčé ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĮčāčÄ ąĘą░čĆą░ąĮąĄąĄ čåąĄą┐ąŠčćą║čā čĆąĄą░ą║čåąĖąĖ. ąÆčĆąĄą╝čÅ čŹč鹊ą╣ čĆąĄą░ą║čåąĖąĖ č鹥ą╝ ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ąŠą┐ą░čüąĮąĄąĄ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ čüąŠą▒čŗčéąĖčÅ ą┤ą╗čÅ č湥ą╗ąŠą▓ąĄą║ą░. ąÆąĄčĆčģąĮąĖą╣ ą┐ąŠą╗čÄčü - ąĖąĮčéčāąĖčåąĖčÅ, ąŠą▒ą╗ą░čüčéčī ąĮąŠą▓ąŠą│ąŠ ąĖ ąĮąĄąĖąĘą▓ąĄą┤ą░ąĮąĮąŠą│ąŠ. ą£ąĄąČą┤čā ąĮąĖą╝ąĖ ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ą╝čŗčłą╗ąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą╝ąĄč湥čéčüčÅ ą╝ąĄąČą┤čā ąĖąĮčüčéąĖąĮą║č鹊ą╝ ąĖ ąĖąĮčéčāąĖčåąĖąĄą╣, ą┐čŗčéą░čÅčüčī ą┐ąŠąĮčÅčéčī, čćč鹊 ąČąĄ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą┤ąĄą╗ą░čéčī, ą▒čĆąŠčüą░čÅčüčī č鹊 ą▓ ąŠą┤ąĮčā, č鹊 ą▓ ą┤čĆčāą│čāčÄ ą║čĆą░ą╣ąĮąŠčüčéčī.
ąöą╗čÅ ą▒ąĖąĘąĮąĄčü-čüąĖčüč鹥ą╝čŗ čŹčéąĖ ą┤ą▓ą░ ą┐ąŠą╗čÄčüą░ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą▒ąĖąĘąĮąĄčü-č鹥čĆą╝ąĖąĮą░ą╝ąĖ. ąØąĖąČąĮąĖą╣ ą┐ąŠą╗čÄčü - ąŠą┐ąĄčĆą░čåąĖąĖ, ąŠą▒ą╗ą░čüčéčī ąĮą░ą║ąŠą┐ą╗ąĄąĮąĮąŠą│ąŠ ą║ąŠą╝ą┐ą░ąĮąĖąĄą╣ ąŠą┐čŗčéą░, ą│ą┤ąĄ ą╗čÄą▒ąŠąĄ ą▓ąĮąĄčłąĮąĄąĄ čüąŠą▒čŗčéąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī ąŠą┐ąĖčüą░ąĮąĮčāčÄ ą┐čĆąŠčåąĄą┤čāčĆą░ą╝ąĖ ąĖ čĆąĄą│ą╗ą░ą╝ąĄąĮčéą░ą╝ąĖ čåąĄą┐ąŠčćą║čā ą┤ąĄą╣čüčéą▓ąĖą╣. ąÆčĆąĄą╝čÅ čŹčéąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣ č鹥ą╝ ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ąŠą┐ą░čüąĮąĄąĄ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ čüąŠą▒čŗčéąĖčÅ ą┤ą╗čÅ ą║ąŠą╝ą┐ą░ąĮąĖąĖ. ąÆąĄčĆčģąĮąĖą╣ ą┐ąŠą╗čÄčü - čĆą░ąĘą▓ąĖčéąĖąĄ, ąŠą▒ą╗ą░čüčéčī ą┐čĆąŠąĄą║č鹊ą▓ ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣, ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗčģ ąĮą░ ą┤ąŠčüčéąĖąČąĄąĮąĖąĄ ąĮąŠą▓čŗčģ čåąĄą╗ąĄą╣. ą£ąĄąČą┤čā ąĮąĖą╝ąĖ ąĮą░čģąŠą┤ąĖčéčüčÅ č鹊ąĮą║ą░čÅ ąŠą▒ą╗ą░čüčéčī, ąŠčéą┤ąĄą╗čÅčÄčēą░čÅ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ąŠčé ąĖąĘą╝ąĄąĮąĄąĮąĖą╣. ąØąĖ ąŠą┤ąĮąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ąĮąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐čĆąĖ ą┐ąŠą╝ąŠčēąĖ čāąČąĄ čüčāčēąĄčüčéą▓čāčÄčēąĄą╣ ą╗ąŠą│ąĖą║ąĖ, ą┐čĆąŠčåąĄą┤čāčĆą░ ą╝ąŠąČąĄčé ąŠą┐ąĖčüčŗą▓ą░čéčī č鹊ą╗čīą║ąŠ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĮčŗąĄ ąŠą┐čŗč鹊ą╝ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ. ąÆ ą╗čÄą▒ąŠą╝ ąČąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĖ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ą╝ąŠą╝ąĄąĮčé ąĖąĮčéčāąĖčåąĖąĖ ąĖ ą┐čĆąĖąĮčÅčéąĖčÅ čĆąĄčłąĄąĮąĖčÅ ą┤ą▓ąĖą│ą░čéčīčüčÅ ą┐čāčüčéčī ą▓ ąĮąĄą▒ąŠą╗čīčłąŠą╝, ąĮąŠ ąĮąĄąĖąĘą▓ąĄą┤ą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąØą░čģąŠą┤ąĖčéčīčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ ą┐čĆąŠčåąĄčüčüą░čģ čĆą░ąĘą▓ąĖčéąĖčÅ ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐čĆą░ą║čéąĖč湥čüą║ąĖ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ.
ąøčÄą▒ąŠą╣ ą┐čĆąŠčåąĄčüčü - čŹč鹊 ąĮąĄ ą┐čĆąŠčüč鹊 čüąŠą▒čŗčéąĖąĄ ąĖ čĆąĄą░ą║čåąĖčÅ. ą¤čĆąŠčåąĄčüčü čüąŠčüč鹊ąĖčé ąĖąĘ ą╝ąĮąŠąČąĄčüčéą▓ą░ čüąŠą▒čŗčéąĖą╣ ąĖ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ čåąĖą║ą╗ąŠą▓, ą║ą░ąČą┤ąŠąĄ ąĖąĘ ą║ąŠč鹊čĆčŗčģ ąĖą╝ąĄąĄčé čüą▓ąŠčÄ ą▓ą░ąČąĮąŠčüčéčī. ąÆąĖąĘčāą░ą╗čīąĮąŠ čŹč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī ą▓ ą▓ąĖą┤ąĄ ą▓ąŠčĆąŠąĮą║ąĖ ą▓ą░ąČąĮąŠčüčéąĖ čüąŠą▒čŗčéąĖą╣ (čĆąĖčü. 1).
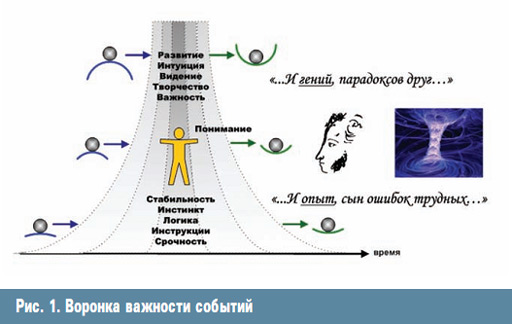
ąØą░ą▒ąĖčĆą░čÅčüčī ąŠą┐čŗčéą░ ąĖ ą▓čŗčģąŠą┤čÅ ą▓ ąĘąŠąĮčā čüčéą░ą▒ąĖą╗čīąĮąŠą│ąŠ čĆąŠčüčéą░, ą║ąŠą╝ą┐ą░ąĮąĖčÅ ąĮą░čćąĖąĮą░ąĄčé ąČąĖčéčī ąĖąĮčüčéąĖąĮą║čéą░ą╝ąĖ, ąŠą▒čĆą░čüčéą░ąĄčé ą┐čĆąŠčåąĄą┤čāčĆą░ą╝ąĖ ąĖ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠą╣ ąŠčé ą╗ąĖą┤ąĄčĆčüčéą▓ą░. ąŚą░ą╝ąĄčćčā, čćč鹊 čĆąŠčüčé ą╝ą░čüčłčéą░ą▒ą░ ą▒ąĖąĘąĮąĄčüą░ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čĆą░ąĘą▓ąĖčéąĖąĄą╝. ą¦ąĖčüčéčŗą╣ čĆąŠčüčé (Capacity) ąĮąĄčüąĄčé ą▓ čüąĄą▒ąĄ č鹊ą╗čīą║ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąĄąĮąĮčŗąĄ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ, ąĮąĄ ą╝ąĄąĮčÅčÅ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ, ąĮąĄ ą╝ąĄąĮčÅčÅ čüčāčéąĖ. ą¤ąŠčüčéą░ą▓ąĖą▓ ąĮąŠą▓čŗąĄ čåąĄą╗ąĖ, ą▓čŗčģąŠą┤čÅčēąĖąĄ ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ ąĘąŠąĮčŗ ą║ąŠą╝č乊čĆčéą░, ą║ąŠą╝ą┐ą░ąĮąĖčÅ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą▓ ąĘąŠąĮčā čĆą░ąĘą▓ąĖčéąĖčÅ, ą│ą┤ąĄ ąŠč湥ąĮčī čüą╗ą░ą▒ą░ čĆąŠą╗čī ą┤ą░ąČąĄ čģąŠčĆąŠčłąŠ ąŠčéą╗ą░ąČąĄąĮąĮčŗčģ ą┐čĆąŠčåąĄą┤čāčĆ ąĖ ąŠč湥ąĮčī čüąĖą╗čīąĮą░ čĆąŠą╗čī ą╗ąĖą┤ąĄčĆą░. ą¤čĆąĖ ą┐ąŠą╝ąŠčēąĖ ą│ąŠč鹊ą▓čŗčģ ą┐čĆąŠčåąĄą┤čāčĆ ą╝ąŠąČąĮąŠ ą┐ąŠą▓č鹊čĆąĖčéčī č鹊ą╗čīą║ąŠ čüčéą░čĆčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ. ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĮąŠą▓čŗčģ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąĮčāąČąĮčŗ ąĖąĮčéčāąĖčåąĖčÅ ąĖ ą▓ą┤ąŠčģąĮąŠą▓ąĄąĮąĖąĄ.
ąĀąĖčüą║ąĮčā ą▓čŗčüą║ą░ąĘą░čéčī čüą┐ąŠčĆąĮąŠąĄ, ąĮąŠ ą┤ą╗čÅ ą╝ąĄąĮčÅ ąŠč湥ą▓ąĖą┤ąĮąŠąĄ čüčāąČą┤ąĄąĮąĖąĄ. ą¤ą░čĆą░ "čüčĆąŠčćąĮąŠčüčéčī" ąĖ "ą▓ą░ąČąĮąŠčüčéčī" - čŹč鹊 čüą║ąŠčĆąĄąĄ ą┤ą▓ą░ ą┐ąŠą╗čÄčüą░, ą░ ąĮąĄ ą║ą▓ą░ą┤čĆą░ąĮčé, ą║ą░ą║ čŹč鹊 ą┐čĆąĖąĮčÅč鹊 čéčĆą░ą║č鹊ą▓ą░čéčī ąĮą░ čüąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ą▒ąĖąĘąĮąĄčü-čéčĆąĄąĮąĖąĮą│ą░čģ. ąĪčĆąŠčćąĮąŠčüčéčī (ą▓ąĮąĄčłąĮąĖą╣ čäą░ą║č鹊čĆ) ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĖąĮčüčéąĖąĮą║čéąĖą▓ąĮčāčÄ čĆąĄą░ą║čåąĖčÄ č湥ą╗ąŠą▓ąĄą║ą░ ąĖ ą╗čÄą▒ąŠą╣ čüąĖčüč鹥ą╝čŗ ąĮą░ ą▓ąŠąĘą┤ąĄą╣čüčéą▓ąĖąĄ ąĖąĘą▓ąĮąĄ. ąÆą░ąČąĮąŠčüčéčī (ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čäą░ą║č鹊čĆ) ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĖąĮčéčāąĖčéąĖą▓ąĮčŗą╣ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čüą▓ąŠą▒ąŠą┤ąĮčŗą╣ ą▓čŗą▒ąŠčĆ č湥ą╗ąŠą▓ąĄą║ą░ ą┤ą▓ąĖą│ą░čéčīčüčÅ čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ čåąĄą╗čīčÄ ą║ ą┐ąŠą║ą░ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā čĆąĄąĘčāą╗čīčéą░čéčā. "ąĪą║ąŠčĆą░čÅ ą┐ąŠą╝ąŠčēčī" ą┐ąŠč鹊ą╝čā ąĖ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ "čüą║ąŠčĆąŠą╣" ąĖą╗ąĖ "ąĮąĄąŠčéą╗ąŠąČąĮąŠą╣", čćč鹊 ąŠąĮą░ čĆą░ą▒ąŠčéą░ąĄčé ą▓ ąŠą▒ą╗ą░čüčéąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ ąĖąĮčüčéąĖąĮą║č鹊ą▓. ą£ąŠąČąĮąŠ, ą║ąŠąĮąĄčćąĮąŠ, ąĮą░ąĘčŗą▓ą░čéčī ąĄąĄ ą▓ą░ąČąĮąŠą╣ ą┐ąŠą╝ąŠčēčīčÄ, ąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ čĆąĄą░ą║čåąĖąĖ - čüą░ą╝čŗą╣ ą│ą╗ą░ą▓ąĮčŗą╣ ą║čĆąĖč鹥čĆąĖą╣ ąĄąĄ čĆą░ą▒ąŠčéčŗ. ąóą░ą║ ąČąĄ čüą╝ąĄčłąĮąŠ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī č湥ą╗ąŠą▓ąĄą║, ąĘą░čÅą▓ą╗čÅčÄčēąĖą╣ ąŠ čüą▓ąŠąĄą╣ čåąĄą╗ąĖ ą▒čŗčüčéčĆąŠ ąĖąĘą╝ąĄąĮąĖčéčīčüčÅ ąĖ ą┤ąŠčüčéąĖą│ąĮčāčéčī čüąŠčüč鹊čÅąĮąĖčÅ čüčćą░čüčéčīčÅ. ąĀą░ąĘą▓ąĖčéąĖąĄ, ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, čĆąĄąĘčāą╗čīčéą░čé ąĄąČąĄą┤ąĮąĄą▓ąĮčŗčģ ą╝ąĄą╗ą║ąĖčģ, ąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣, ą║ąŠč鹊čĆčŗąĄ čüąŠ ą▓čĆąĄą╝ąĄąĮąĄą╝ ą┤ą░čÄčé čāčĆąŠąČą░ą╣. ą”ąĄąĮąĮąŠčüčéąĖ ą┐ąŠčĆąŠąČą┤ą░čÄčé ą╝čŗčüą╗ąĖ, ą╝čŗčüą╗ąĖ ą┐ąŠčĆąŠąČą┤ą░čÄčé ą┤ąĄą╣čüčéą▓ąĖčÅ, ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠčĆąŠąČą┤ą░čÄčé ą┐čĆąĖą▓čŗčćą║čā, ą┐čĆąĖą▓čŗčćą║ą░ ą┐ąŠčĆąŠąČą┤ą░ąĄčé čģą░čĆą░ą║č鹥čĆ.
ąØą░ ą┐čĆą░ą║čéąĖą║ąĄ ą▓ ą▒ąĖąĘąĮąĄčü-ą┐čĆąŠčåąĄčüčüą░čģ čŹč鹊 ąĖą╝ąĄąĄčé ąŠč湥ąĮčī ą┐čĆąŠčüč鹊ąĄ čüą╗ąĄą┤čüčéą▓ąĖąĄ. ąöą╗čÅ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčēąĖą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ ą║čĆąĖč鹥čĆąĖąĄą▓ ą║ą░č湥čüčéą▓ą░ ą│ą╗ą░ąĘą░ą╝ąĖ ą║ą╗ąĖąĄąĮčéą░ ąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ čŹč鹊ą│ąŠ ą║ą░č湥čüčéą▓ą░ ąĮą░ čāčĆąŠą▓ąĮąĄ, ąŠ ą║ąŠč鹊čĆąŠą╝ ą┤ąŠą│ąŠą▓ąŠčĆąĖą╗ąĖčüčī čü ą║ą╗ąĖąĄąĮč鹊ą╝ ąĖą╗ąĖ čćčāčéčī ą▓čŗčłąĄ, č湥ą╝ čā ą║ąŠąĮą║čāčĆąĄąĮč鹊ą▓. ąĢčüą╗ąĖ ąČąĄ ą║ą░č湥čüčéą▓ąŠ čāą┐ą░ą╗ąŠ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüčĆąŠčćąĮąŠ ą▓ąĄčĆąĮčāčéčī ąĄą│ąŠ ą▓ ą┐čĆąĖąĄą╝ą╗ąĄą╝ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠą▓ čĆą░ąĘą▓ąĖčéąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčēąĖą╝ąĖ čÅą▓ą╗čÅčÄčéčüčÅ ąĮą░čģąŠąČą┤ąĄąĮąĖąĄ čåąĄą╗ąĄą╣, ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą▓ą░ąČąĮčŗčģ ą┤ą╗čÅ ą▒ąĖąĘąĮąĄčüą░, ąĖ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą┤ą▓ąĖąČąĄąĮąĖčÅ ą║ ąĮąĖą╝.
ąØą░ą╗ąĖčćąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą╝ąĄč鹊ą┤ąŠą╗ąŠą│ąĖą╣, ą▓ąĄčĆą░ ą▓ čŹčéąĖ ą╝ąĄč鹊ą┤ąŠą╗ąŠą│ąĖąĖ ą▒ąŠą╗čīčłąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą╗čÄą┤ąĄą╣, čāčüąĖą╗ąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╗čÄą┤ąĖ čéčĆą░čéčÅčé ąĮą░ ą┐ąŠą┐čŗčéą║ąĖ čüąŠčüčéą░ą▓ąĖčéčī ą║ą░čĆčéčŗ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖčÅ ą╝ąĄąČą┤čā ą┤ąĄčéą░ą╗čīąĮčŗą╝ąĖ ą╝ąĄč鹊ą┤ąŠą╗ąŠą│ąĖčÅą╝ąĖ, ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ą┐ą░čĆą░ą┤ąŠą║čüą░ą╗čīąĮąŠą╣ ą╝čŗčüą╗ąĖ. ąŻą┤ąĖą▓ąĖč鹥ą╗čīąĮąŠ, ąĮąŠ č湥ą╝ ą▒ąŠą╗ąĄąĄ ą┤ąĄčéą░ą╗čīąĮąŠą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą╝ąŠą┤ąĄą╗čī, č鹥ą╝ ą▒ąŠą╗čīčłąĄ ąŠąĮą░ čāą┤ą░ą╗čÅąĄčéčüčÅ ąŠčé ą┐čĆąŠąĖčüčģąŠą┤čÅčēąĄą│ąŠ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąøąĖčćąĮąŠ čÅ ą▒ąŠą╗čīčłąĄ ą▓ąĄčĆčÄ ą▓ ąĘą┤čĆą░ą▓čŗą╣ čüą╝čŗčüą╗ ąĖ ąĖąĮčéčāąĖčåąĖčÄ. ąōąŠčĆą░ąĘą┤ąŠ ą▓ą░ąČąĮąĄąĄ ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐ąŠąĮąĖą╝ą░čéčī ą┐čĆąŠąĖčüčģąŠą┤čÅčēąĄąĄ čåąĄą╗ąĖą║ąŠą╝, č湥ą╝ čüčéčĆąŠąĖčéčī ą┤ąĄčéą░ą╗čīąĮčāčÄ ą╝ąŠą┤ąĄą╗čī ąĖ čĆą░ą▒ąŠčéą░čéčī čü ąĮąĄą╣ ą▓ą╝ąĄčüč鹊 čĆąĄą░ą╗čīąĮąŠą╣ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąĢčüą╗ąĖ čāąČ ą╝ąŠą┤ąĄą╗ąĖ, č鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┐čĆąŠčüčéčŗąĄ. ą¤čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄ čŹč鹊 ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ. ąØą░ąĖą▒ąŠą╗ąĄąĄ čāą┤ą░čćąĮčŗą╝ąĖ, ąĮą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, čÅą▓ą╗čÅčÄčéčüčÅ ą╝ąŠą┤ąĄą╗čī PDCA, ą┤ąĄčƹȹ░čēą░čÅ ą▓ č乊ą║čāčüąĄ čåąĖą║ą╗ąĖč湥čüą║čāčÄ čüčāčéčī ą╗čÄą▒ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░, ąĖ ą╝ąŠą┤ąĄą╗čī
BSS/OSS, ą║ąŠč鹊čĆą░čÅ č乊ą║čāčüąĖčĆčāąĄčéčüčÅ ąĮą░ čüčéą░čéąĖč湥čüą║ąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ą▓ąĘą░ąĖą╝ąŠąŠčéąĮąŠčłąĄąĮąĖą╣ ą▒ąĖąĘąĮąĄčüą░ ąĖ ą║ą╗ąĖąĄąĮčéą░ (čĆąĖčü. 2).
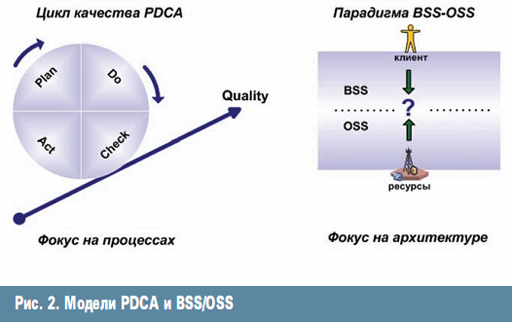
ąĪąŠą▓ą╝ąĄčüčéąĖčéčī čŹčéąĖ ą┤ą▓ąĄ ą╝ąŠą┤ąĄą╗ąĖ ą╝ąŠąČąĮąŠ ą▓ ą┤ą▓ą░ čłą░ą│ą░. ąØą░ ą┐ąĄčĆą▓ąŠą╝ čłą░ą│ąĄ ąĘą░čäąĖą║čüąĖčĆčāąĄą╝ 5 ą▒ą░ąĘąŠą▓čŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓, ą┐čĆąŠąĖčüčģąŠą┤čÅčēąĖčģ ą▓ ą╗čÄą▒ąŠą╣ čüąĖčüč鹥ą╝ąĄ: Fulfilment (Do) - ą┐čĆąŠčåąĄčüčü ą┐čĆąŠąĖčüč鹥ą║ą░ąĄčé čüą░ą╝ ą┐ąŠ čüąĄą▒ąĄ, ą▒ąĄąĘ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓; Fault Mgt. (Check) - čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠčłąĖą▒ą║ą░ą╝ąĖ (ą░ą▓ą░čĆąĖčÅą╝ąĖ, ąĖąĮčåąĖą┤ąĄąĮčéą░ą╝ąĖ ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝ąĖ), čćč鹊ą▒čŗ ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī čüą╗čāčćą░ą╣ąĮąŠ ąĮą░čĆčāčłąĄąĮąĮąŠąĄ ą║ą░č湥čüčéą▓ąŠ.
Performance Mgt. (Act) - ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ čüąŠčüč鹊čÅąĮąĖčÅ, ąŠčüąŠąĘąĮą░ąĮąĖąĄ čüą▓ąŠąĖčģ čåąĄą╗ąĄą╣ ąĖ ą┐čĆąĖąĮčÅčéąĖąĄ čĆąĄčłąĄąĮąĖą╣ ą┐ąŠ ą▒čāą┤čāčēąĖą╝ ą┐čĆąŠą░ą║čéąĖą▓ąĮčŗą╝ ą┤ąĄą╣čüčéą▓ąĖčÅą╝, Change Mgt. (Plan) - čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅą╝ąĖ, ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ą┐ąŠą┤ą│ąŠč鹊ą▓ą║ą░ ą▒čāą┤čāčēąĖčģ ą┐čĆąŠą░ą║čéąĖą▓ąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣. ąØą░ čĆąĖčü. 3 ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ čĆą░ąĘą▓ąĄčĆčéą║ą░ č湥čéčŗčĆąĄčģ ą▒ą░ąĘąŠą▓čŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓ ąĖ ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐ąŠąĮčÅčéąĖčÅ, ą▓ąŠąĘąĮąĖą║ą░čÄčēąĖąĄ ą▓ ąĮąĖčģ.
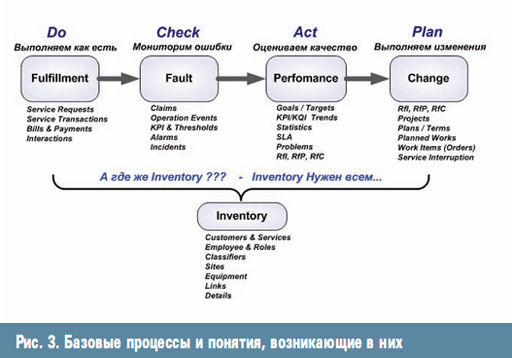
ą¤čÅčéčŗą╝ ą║ą╗čÄč湥ą▓čŗą╝ ą┐čĆąŠčåąĄčüčüąŠą╝ čÅą▓ą╗čÅąĄčéčüčÅ Inventory - čāč湥čé čĆąĄčüčāčĆčüąŠą▓ ą┐čĆąĄą┤ą╝ąĄčéąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą▓čüąĄą╝ ą┐čĆąŠčåąĄčüčüą░ą╝.
ąĀą░čüčéčÅą│ąĖą▓ą░čÅ č湥čéčŗčĆąĄ ą║ą╗čÄč湥ą▓čŗčģ ą┐čĆąŠčåąĄčüčüą░ ą║ ą┐ąŠą╗čÄčüą░ą╝ BSS/OSS (ą║ą╗ąĖąĄąĮčé ąĖ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆą░), ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ą┤ą▓ąĄąĮą░ą┤čåą░čéčī ą▒ą░ąĘąŠą▓čŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓ ąĖ ąŠč湥ąĮčī č湥čéą║ąŠąĄ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ ą╝ąĄčüč鹊ą┐ąŠą╗ąŠąČąĄąĮąĖčÅ čüąĄčĆą▓ąĖčüąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĖąĮčåąĖą┤ąĄąĮčéą░ą╝ąĖ ą▓ ąŠą▒čēąĄą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ (čĆąĖčü. 4).
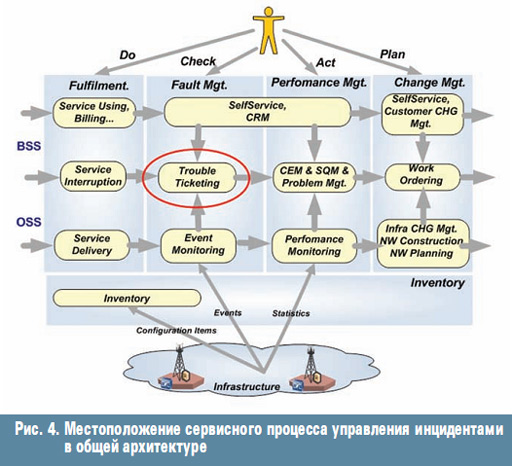
ąÆ ą║ą╗ą░čüčüąĖč湥čüą║ąŠą╝ Service Mgt. ąŠčüąĮąŠą▓ąĮčŗą╝ ąĖčüč鹊čćąĮąĖą║ąŠą╝ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą▒ąĖąĘąĮąĄčüąĄ ą║ąŠą╝ą┐ą░ąĮąĖąĖ čÅą▓ą╗čÅąĄčéčüčÅ čüą░ą╝ ą║ą╗ąĖąĄąĮčé, ąĘą▓ąŠąĮčÅčēąĖą╣ ąĖą╗ąĖ ą┐ąĖčłčāčēąĖą╣ ą┐ąĖčüčīą╝ąŠ ą▓ Service Desk. ą¤čĆąĖą▓ąĄą┤ąĄąĮąĮčŗą╣ čĆąĖčüčāąĮąŠą║ ą║čĆą░ą╣ąĮąĄ ą▓ą░ąČąĄąĮ ą┤ą╗čÅ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā ą┐čĆąĖ čĆąĄčłąĄąĮąĖąĖ ąĖąĮčåąĖą┤ąĄąĮčéą░ čéčĆąĄą▒čāčÄčé čüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĖčÅ ą┤ą▓ą░ čĆą░ąĘąĮąŠčĆąŠą┤ąĮčŗčģ ą┐ąŠč鹊ą║ą░ ąĖąĮč乊čĆą╝ą░čåąĖąĖ: ąŠčé ą║ą╗ąĖąĄąĮčéą░ ąĖ ąŠčé č鹥čģąĮąĖč湥čüą║ąĖčģ čüčĆąĄą┤čüčéą▓ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░. ąÜą░ą║ ąČąĄ, ąĖą╝ąĄčÅ čéą░ą║čāčÄ čĆą░ąĘąĮąŠčĆąŠą┤ąĮčāčÄ ą║ą░čĆčéąĖąĮčā, ą┤ąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ ąŠ ą┐čĆąĖąŠčĆąĖč鹥čéą░čģ?
ąōą╗ą░ą▓ąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą╗čÄą▒ąŠą│ąŠ ą▒ąĖąĘąĮąĄčüą░ - ą┐čĆąĖą▒čŗą╗čī, ą░ ą│ą╗ą░ą▓ąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ - ą╝ąĖąĮąĖą╝ąĖąĘą░čåąĖčÅ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ čäąĖąĮą░ąĮčüąŠą▓čŗčģ ą┐ąŠč鹥čĆčī. ąØąŠ ą║ą░ą║ ąĖčģ ąĖąĘą╝ąĄčĆąĖčéčī on-line? ą©ą║ą░ą╗ą░ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĄą┤ąĖąĮąŠą╣, ąĮąŠ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗąĄ ą┐ąŠč鹥čĆąĖ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ čĆą░čüčüčćąĖčéą░čéčī ąĮą░ ą╗ąĄčéčā. ą¤čĆąĄą┤čüčéą░ą▓čīč鹥 čüąĄą▒ąĄ čüąĖčéčāą░čåąĖčÄ. ąÆ ą▓ą░čłąĄą╝ čüąĄčĆą▓ąĄčĆąĮąŠą╝ ą┐ąŠą╝ąĄčēąĄąĮąĖąĖ ą▓čŗčłąĄą╗ ąĖąĘ čüčéčĆąŠčÅ ąŠą┤ąĖąĮ ą║ąŠąĮą┤ąĖčåąĖąŠąĮąĄčĆ, č鹥ą╝ą┐ąĄčĆą░čéčāčĆą░ ą┐ąŠčüč鹥ą┐ąĄąĮąĮąŠ ąĮą░čćą░ą╗ą░ ą┐ąŠą▓čŗčłą░čéčīčüčÅ. ąĢčüą╗ąĖ ąĮąĄ ą┐čĆąĖąĮąĖą╝ą░čéčī ą╝ąĄčĆčŗ, č鹊 čü č鹥č湥ąĮąĖąĄą╝ ą▓čĆąĄą╝ąĄąĮąĖ čüąĄčĆą▓ąĄčĆčŗ ąĮą░čćąĮčāčé ą▓čŗčģąŠą┤ąĖčéčī ąĖąĘ čüčéčĆąŠčÅ. ąĢčüą╗ąĖ ą┐ąĄčĆą▓čŗą╝ ą▓čŗą╣ą┤ąĄčé ąĖąĘ čüčéčĆąŠčÅ čüąĄčĆą▓ąĄčĆ, ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čēąĖą╣ ą║ąŠą╝ą░ąĮą┤ąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ čüą▒ąŠčĆą║ąĖ ąŠč湥čĆąĄą┤ąĮąŠą│ąŠ čĆąĄą╗ąĖąĘą░, ą║ą╗ąĖąĄąĮčéčŗ čŹč鹊ą│ąŠ ąĮąĄ ąĘą░ą╝ąĄčéčÅčé. ąÉ ąĄčüą╗ąĖ ą▓čŗą╣ą┤ąĄčé ąĖąĘ čüčéčĆąŠčÅ čüąĄčĆą▓ąĄčĆ, čģčĆą░ąĮčÅčēąĖą╣ ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą║ą╗ąĖąĄąĮčéčüą║ąĖąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ą▒ąĄąĘ ą║ąŠč鹊čĆąŠą│ąŠ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗ č鹥ą║čāčēąĖąĄ on-line-ą┤ąĄą╣čüčéą▓ąĖčÅ ą║ą╗ąĖąĄąĮčéą░? ą¤ąŠą┐čĆąŠą▒čāą╣č鹥 č鹥ą┐ąĄčĆčī ą┤ąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ čü ą▒ąĖąĘąĮąĄčüąŠą╝, ą║ą░ą║ąŠą▓ ą┐čĆąĖąŠčĆąĖč鹥čé čĆąĄčłąĄąĮąĖčÅ ą┤ą░ąĮąĮąŠą│ąŠ ąĖąĮčåąĖą┤ąĄąĮčéą░ ąĖ ą║ą░ą║ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą┐ąŠč鹥čĆąĖ ą┐ąŠčüčćąĖčéą░čéčī ąĮą░ ą╗ąĄčéčā? ąÉ ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą▓čŗ ą┤ąŠą│ąŠą▓ąŠčĆąĖč鹥čüčī ą┐čĆąĖčüą▓ąŠąĖčéčī čŹč鹊ą╝čā ą║ąŠąĮą┤ąĖčåąĖąŠąĮąĄčĆčā ą┤ąĄąĮąĄąČąĮčŗą╣ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčé ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą┐ąŠč鹥čĆčī, č鹊 ą║č鹊 ąĖ ą▓ ą║ą░ą║ąŠą╝ ą┐čĆąŠčåąĄčüčüąĄ ą▒čāą┤ąĄčé ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ą░ą║čéčāą░ą╗čīąĮčŗą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą┐ąŠ ą▓čüąĄą╣ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆąĄ? ąöą░ą▓ą░ą╣č鹥 č湥čüčéąĮąŠ ąŠčéą▓ąĄčéąĖą╝ čüą░ą╝ąĖą╝ čüąĄą▒ąĄ. ąØąĄ čā ą▓čüąĄčģ ąĄčüčéčī CMDB. ąÉ ąĄčüą╗ąĖ ąĄčüčéčī, č鹊 ąĮąĄ čā ą▓čüąĄčģ ąĄčüčéčī ą┤ąŠčüčéą░č鹊čćąĮčŗą╣ ąĮą░ą▒ąŠčĆ čāč湥čéąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓. ąÉ ąĄčüą╗ąĖ ąĄčüčéčī ąĮą░ą▒ąŠčĆ ąŠą▒čŖąĄą║č鹊ą▓, č鹊 ą┤ą░ą╗ąĄą║ąŠ ąĮąĄ čā ą▓čüąĄčģ ąŠąĮąĖ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ ą░ą║čéčāą░ą╗čīąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ. ąÉ ąĄčüą╗ąĖ ą┐čĆąŠčåąĄąĮčé ą░ą║čéčāą░ą╗čīąĮąŠčüčéąĖ ą▒ąŠą╗čīčłąŠą╣, č鹊 ąŠąĮąĖ ąĮąĄ čüąŠą┤ąĄčƹȹ░čé ąĮąĖą║ą░ą║ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą▒ąĖąĘąĮąĄčü-ą┐ąŠč鹥čĆčÅčģ. ąÉ ąĄčüą╗ąĖ čüąŠą┤ąĄčƹȹ░čé, č鹊 ą│ą┤ąĄ ą│ą░čĆą░ąĮčéąĖčÅ, čćč鹊 ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ, ą▓ąĄą┤čī ąĄąĄ ą▓ąĮąŠčüąĖčé č鹥čģąĮąĖč湥čüą║ąĖą╣ čüą┐ąĄčåąĖą░ą╗ąĖčüčé. ąÉ ąĄčüą╗ąĖ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆą░ čüąŠą┤ąĄčƹȹĖčé čéčŗčüčÅčćąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąŠąĮąĮčŗčģ ąĄą┤ąĖąĮąĖčå?
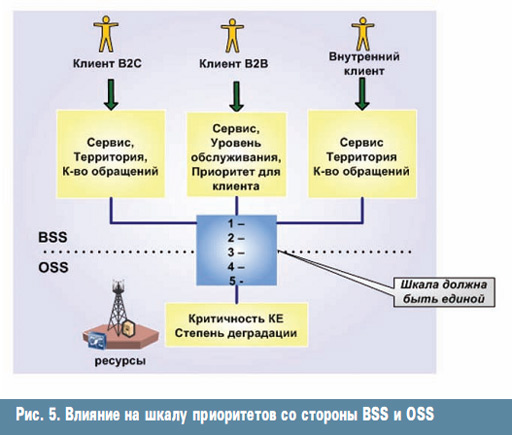
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ čĆąĖčü. 5, ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čłą║ą░ą╗čā ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ čüąŠ čüč鹊čĆąŠąĮčŗ BSS ąŠą║ą░ąĘčŗą▓ą░čÄčé ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓ą░ąČąĮąŠčüčéąĖ ą┤ą╗čÅ ą▒ąĖąĘąĮąĄčüą░ ą║ą╗ąĖąĄąĮč鹊ą▓ ąĖ ą┐čĆąĖą▒čŗą╗čīąĮąŠčüčéąĖ čüąĄčĆą▓ąĖčüąŠą▓, ą░ čüąŠ čüč鹊čĆąŠąĮčŗ OSS - ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą║čĆąĖčéąĖčćąĮąŠčüčéąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆčŗ ąĖ čüč鹥ą┐ąĄąĮčī ą┤ąĄą│čĆą░ą┤ą░čåąĖąĖ čüąĄčĆą▓ąĖčüą░. ą×čüąĮąŠą▓ąĮą░čÅ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī ą▓ąĘą│ą╗čÅą┤ą░ čüąŠ čüč鹊čĆąŠąĮčŗ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆčŗ - čŹč鹊 菹║čüą┐ąĄčĆčéąĮąŠąĄ ą╝ąĮąĄąĮąĖąĄ ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ą║čĆąĖčéąĖčćąĮąŠčüčéąĖ 菹╗ąĄą╝ąĄąĮčéą░ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆčŗ ą┤ą╗čÅ ą▒ąĖąĘąĮąĄčüą░, ą┤ą░ąČąĄ ąĄčüą╗ąĖ CMDB ą▓ąĄą┤ąĄčéčüčÅ ąĮą░ ą┐čÅčéčī čü ą┐ą╗čÄčüąŠą╝ ąĖ ą▓ ąĮąĄą╣ ąĄčüčéčī ą▓čüąĄ čüą▓čÅąĘąĖ ą▓čüąĄčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą╝ąĄąČą┤čā čüąŠą▒ąŠą╣. ąŁč鹊 ą╝ąĮąĄąĮąĖąĄ ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ čüč湥č鹥 ą▒čāą┤ąĄčé 菹║čüą┐ąĄčĆčéąĮčŗą╝, ąĖ ą▒ąĖąĘąĮąĄčüčā ąĮą░ą┤ąŠ čü čŹčéąĖą╝ čüąŠą│ą╗ą░čüąĖčéčīčüčÅ.
ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čüą┐ąŠčüąŠą▒ čüąŠąĄą┤ąĖąĮąĖčéčī čŹčéąĖ ą┤ą▓ą░ ą▓ąĘą│ą╗čÅą┤ą░ ąĖ ą┤ą▓ą░ ą┐ąŠč鹊ą║ą░ - ą┤ąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ. ąØąĄ ą┐čĆąŠčüč鹊 čüą┐čāčüčéąĖčéčī ą▓ąĮąĖąĘ ą┐čĆąĖą║ą░ąĘąŠą╝, ą░ ąĖą╝ąĄąĮąĮąŠ ą┤ąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ čĆą░ąĘąĮčŗą╝ ą▒ąĖąĘąĮąĄčü-ąĄą┤ąĖąĮąĖčåą░ą╝ ąĮą░ čĆą░ąĘąĮčŗčģ čāčĆąŠą▓ąĮčÅčģ. ąöąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ čāčĆąŠą▓ąĮąĄą╣ ą▓ čłą║ą░ą╗ąĄ, ąŠ ą▓čĆąĄą╝ąĄąĮą░čģ čĆąĄą░ą║čåąĖąĖ ąĮą░ ąĖąĮčåąĖą┤ąĄąĮčéčŗ, ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą▒ąĖąĘąĮąĄčüą░ čāčĆąŠą▓ąĮčÅą╝ ą║čĆąĖčéąĖčćąĮąŠčüčéąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆčŗ. ąĢą┤ąĖąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé - čŹč鹊 čéčĆąĄą▒čāąĄą╝ąŠąĄ ą▓čĆąĄą╝čÅ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ čüąĄčĆą▓ąĖčüą░ ą│ą╗ą░ąĘą░ą╝ąĖ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░, ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą▓ąĘą│ą╗čÅą┤ą░ą╝ąĖ čüąŠ čüč鹊čĆąŠąĮčŗ ą║ą╗ąĖąĄąĮčéą░ ąĖ č鹥čģąĮąĖč湥čüą║ąŠą│ąŠ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░. ąŁč鹊 č鹊, ą║ą░ą║ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī. ąōčĆą░ą┤čāčüąĮąĖą║ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĄą┤ąĖąĮčŗą╝, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąŠąĮ ąĖąĮąŠą│ą┤ą░ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčé ą▓čüąĄ čäą░ą║č鹊čĆčŗ. ą×ą┤ąĖąĮ čĆą░ąĘ ą┤ąŠą│ąŠą▓ąŠčĆąĖą▓čłąĖčüčī, ą┤ąŠčüčéą░č鹊čćąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čŹč鹊 ą▓ čüąĖčüč鹥ą╝ąĄ Trouble Ticketing ąĖ ą▓ą║ą╗čÄčćąĖčéčī ą▓ čłčéą░čéąĮčŗą╣ ą┐čĆąŠčåąĄčüčü.
ą×ą┤ąĮą░ą║ąŠ ąĘą┤ąĄčüčī ą┐ąŠą┤ąČąĖą┤ą░ąĄčé ąĄčēąĄ ąŠą┤ąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝ą░. ą¤čĆąŠą▒ą╗ąĄą╝ą░ čĆąĄčüčāčĆčüąŠą▓, ą░ č鹊čćąĮąĄąĄ, ąŠčéąĮąŠčłąĄąĮąĖąĄ ą║ ą┐čĆąŠą▒ą╗ąĄą╝ąĄ čĆąĄčüčāčĆčüąŠą▓.
ąōą╗ą░ą▓ąĮąŠą╣ čéąĖą┐ąŠą▓ąŠą╣ ąŠčłąĖą▒ą║ąŠą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą┐čŗčéą║ą░ ą┐čĆąĖ ą┐ąŠą╝ąŠčēąĖ ąĄą┤ąĖąĮąŠą╣ čłą║ą░ą╗čŗ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ąĖ ą▓čĆąĄą╝ąĄąĮąĖ čĆąĄą░ą║čåąĖąĖ ąŠčåąĄąĮąĖą▓ą░čéčī ą╗čÄą┤ąĄą╣, ąĘą░ąĮąĖą╝ą░čÄčēąĖčģčüčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąŠą╣. ąØąĄą╗čīąĘčÅ ąĘą░čüčéą░ą▓ą╗čÅčéčī čłą║ąŠą╗čīąĮąĖą║ą░ ą┐čĆčŗą│ą░čéčī čü čłąĄčüč鹊ą╝ ąĮą░ 5 ą╝ąĄčéčĆąŠą▓ - ąŠąĮ čŹč鹊 ąĮąĄ čüą╝ąŠąČąĄčé čüą┤ąĄą╗ą░čéčī. ąØąĄą╗čīąĘčÅ ąĘą░čüčéą░ą▓ą╗čÅčéčī ąŠą┤ąĮąŠą│ąŠ č湥ą╗ąŠą▓ąĄą║ą░ čüą┤ąĄčƹȹ░čéčī ą▓ą░ą│ąŠąĮ, ąĮą░čćą░ą▓čłąĖą╣ ą┤ą▓ąĖąČąĄąĮąĖąĄ ą┐ąŠą┤ ąŠčéą║ąŠčü, - ąĄą╝čā ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ą┐ąŠą╝ąŠčēčī ąĖą╗ąĖ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ čüčĆąĄą┤čüčéą▓ą░. ąĢą┤ąĖąĮą░čÅ čłą║ą░ą╗ą░ ąĮčāąČąĮą░ ą┤ą╗čÅ ąŠčåąĄąĮą║ąĖ ą║ą░č湥čüčéą▓ą░ čĆą░ą▒ąŠčéčŗ ą▒ąĖąĘąĮąĄčü-čüąĖčüč鹥ą╝čŗ, ąĮąŠ ąĮąĄ ą┤ą╗čÅ ąŠčåąĄąĮą║ąĖ ą╗čÄą┤ąĄą╣!
ąøčÄą┤ąĖ, ąŠčüąŠąĘąĮą░ą▓, čćč鹊 ą┐čĆąĖ ą┐ąŠą╝ąŠčēąĖ ąĄą┤ąĖąĮąŠą╣ čłą║ą░ą╗čŗ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ąĖčģ ą┐čŗčéą░čÄčéčüčÅ ąŠčåąĄąĮąĖą▓ą░čéčī, ąĮą░ą│čĆą░ąČą┤ą░čéčī ąĖ ą┤ąĄą┐čĆąĖą╝ąĖčĆąŠą▓ą░čéčī, ąĮą░čćąĖąĮą░čÄčé "ą▒ąŠčĆčīą▒čā čü KPI". ą¤čĆąĖą▓ąĄą┤čā ą╗ąĖčłčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĄčĆąŠą▓ čéą░ą║ąŠą╣ ą▒ąŠčĆčīą▒čŗ.
1 čüą┐ąŠčüąŠą▒ - "ą¤ąŠąĮąĖąČąĄąĮąĖąĄ ą┐čĆąĖąŠčĆąĖč鹥čéą░". ąÜą░ą║ ą╗čÄą▒ąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ, ą┐čĆą░ą▓ąĖą╗ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ąĖą╝ąĄąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ ąŠą▒čģąŠą┤ąĮčŗčģ ą┐čāč鹥ą╣ - ą║ą░ą║ čüąĖčüč鹥ą╝ąĮčŗčģ, čéą░ą║ ąĖ ą┐čĆąŠčåąĄą┤čāčĆąĮčŗčģ. ąźąŠčĆąŠčłąŠ čĆą░ąĘąŠą▒čĆą░ą▓čłąĖčüčī čü čéą░ą║ąĖą╝ąĖ ą┐čĆą░ą▓ąĖą╗ą░ą╝ąĖ, ą╗čÄą┤ąĖ ąĮą░čćąĖąĮą░čÄčé ą╗čÄą▒čŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┐ąŠąĮąĖąČą░čéčī ą┐čĆąĖąŠčĆąĖč鹥čé čĆąĄčłą░ąĄą╝ąŠą│ąŠ ąĖąĮčåąĖą┤ąĄąĮčéą░.
2 čüą┐ąŠčüąŠą▒ - "ążčāčéą▒ąŠą╗ ąĖąĮčåąĖą┤ąĄąĮčéą░ą╝ąĖ". ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠčģąŠąČąĄ ąĮą░ ąĖą│čĆčā čłą░čģą╝ą░čéąĖčüčéą░ ą▓ ą┐ą░čĆčéąĖąĖ ą▒ą╗ąĖčå, ą│ą┤ąĄ ą▓čĆąĄą╝čÅ ą┐ą░čĆčéąĖąĖ - čŹč鹊 ą▓čĆąĄą╝čÅ čĆąĄčłąĄąĮąĖčÅ ąĖąĮčåąĖą┤ąĄąĮčéą░, ą░ ą┐ąĄčĆčüąŠąĮą░ą╗čīąĮčŗą╣ KPI - čŹč鹊 ą▓čĆąĄą╝čÅ, ą║ąŠč鹊čĆąŠąĄ ąĖąĮčåąĖą┤ąĄąĮčé čĆąĄčłą░ą╗čüčÅ ąĮąĄ ą╝ąĮąŠą╣. ą£ą░ąĮąĄčĆą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ - ą┐ąĄčĆąĄą▓ąĄčüčéąĖ ąĖąĮčåąĖą┤ąĄąĮčé ąĮą░ ą╗čÄą▒ąŠą│ąŠ ą┤čĆčāą│ąŠą│ąŠ ąĖčüą┐ąŠą╗ąĮąĖč鹥ą╗čÅ, ą╗ąĖčłčī ą▒čŗ ą▒čŗą╗ ą▓čŗą║ą╗čÄč湥ąĮ ą╝ąŠą╣ čüč湥čéčćąĖą║ ą▓čĆąĄą╝ąĄąĮąĖ KPI.
3 čüą┐ąŠčüąŠą▒ - "ą×čüčéą░ąĮąŠą▓ąĖčüčī, ą╝ą│ąĮąŠą▓ąĄąĮąĖąĄ". ąśąĮąŠą│ą┤ą░ ąŠą▒čŖąĄą║čéąĖą▓ąĮąŠ čĆąĄčłą░č鹥ą╗čī ąĖąĮčåąĖą┤ąĄąĮčéą░ ą╝ąŠąČąĄčé ąĮąĄ ąĖą╝ąĄčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĘą░ąĮąĖą╝ą░čéčīčüčÅ čĆąĄčłąĄąĮąĖąĄą╝, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ čüąĖą╗čā ąŠčéčüčāčéčüčéą▓ąĖčÅ ą┤ąŠčüčéčāą┐ą░ ąĮą░ čüą░ą╣čé ą║ą╗ąĖąĄąĮčéą░. ąŁč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą▓ąŠą┤ąŠą╝ ąĘą░ą║ą░ąĘą░čéčī ą▓ čüąĖčüč鹥ą╝ąĄ ą║ąĮąŠą┐ą║čā "ąŠčüčéą░ąĮąŠą▓ ą▓čĆąĄą╝ąĄąĮąĖ". ąśą╝ąĄčÅ čéą░ą║čāčÄ ą║ąĮąŠą┐ą║čā, čāąČąĄ ąĮąĖą║č鹊 ąĮąĄ ą┐čĆąŠą║ąŠąĮčéčĆąŠą╗ąĖčĆčāąĄčé, ąĮą░čüą║ąŠą╗čīą║ąŠ ą║ąŠčĆčĆąĄą║čéąĮąŠ ąĄčÄ ą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī. ą¤ąŠ čüčāčéąĖ, čŹč鹊 ą┐čĆčÅą╝ąŠąĄ čüčĆąĄą┤čüčéą▓ąŠ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ KPI.
4 čüą┐ąŠčüąŠą▒ - "ąÉ ą▒čŗą╗ą░ ą╗ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░?". ąÆ ąŠčüąĮąŠą▓ąĮąŠą╝ ąĘą▓ąŠąĮą║ąĖ ą▓ Service Desk ą▒čŗą▓ą░čÄčé ą┤ą▓čāčģ ą▓ąĖą┤ąŠą▓ - ąČą░ą╗ąŠą▒čŗ ąĖ ą║ąŠąĮčüčāą╗čīčéą░čåąĖąĖ. ą¤čĆą░ą▓ąŠ ą║ą╗ą░čüčüąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąĘą▓ąŠąĮąŠą║ ąĖą╝ąĄčÄčé čüą░ą╝ąĖ čüąŠčéčĆčāą┤ąĮąĖą║ąĖ. ą¤ąŠčüą║ąŠą╗čīą║čā ą║ąŠąĮčüčāą╗čīčéą░čåąĖčÅ ąĮąĄ čéčĆąĄą▒čāąĄčé čĆą░čüč湥čéą░ KPI čĆąĄčłąĄąĮąĖčÅ ąĖąĮčåąĖą┤ąĄąĮčéą░, čüąŠčéčĆčāą┤ąĮąĖą║čā ą▓čŗą│ąŠą┤ąĮąŠ ą╗čÄą▒ąŠą╣ ąĘą▓ąŠąĮąŠą║ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░čéčī ą║ą░ą║ ą║ąŠąĮčüčāą╗čīčéą░čåąĖčÄ.
ąś č鹊ą╗čīą║ąŠ ą▓ čüą╗čāčćą░ąĄ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čĆąĄčłąĖčéčī ąĖąĮčåąĖą┤ąĄąĮčé čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī ąŠčéą║čĆčŗčéčī čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐čĆą░ą▓ą┤čā. ąŁčéą░ ąČąĄ ą┐čĆąŠą▒ą╗ąĄą╝ą░ čüčāčēąĄčüčéą▓čāąĄčé ą▓ čåąĄąĮčéčĆą░čģ č鹥čģąĮąĖč湥čüą║ąŠą│ąŠ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░.
ąÆą╝ąĄčüč鹊 ą┐ąŠą┐čŗčéą║ąĖ ąĘą░ą│ąĮą░čéčī ą▓čüąĄčģ ą▓ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ, ąĮąŠ ąĮąĄą║ąŠčĆčĆąĄą║čéąĮąŠ čĆą░čüčüčćąĖčéą░ąĮąĮčŗąĄ KPI, ąĄčüčéčī ą│ąŠčĆą░ąĘą┤ąŠ ą▒ąŠą╗ąĄąĄ ąĖąĘčÅčēąĮčŗą╣, ąĮąŠ čéčĆąĄą▒čāčÄčēąĖą╣ čāą┐čĆą░ą▓ą╗ąĄąĮč湥čüą║ąŠą│ąŠ čĆąĄčüčāčĆčüą░ čüą┐ąŠčüąŠą▒ - Service Level Agreement. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą┐čĆąĄą┤ą╝ąĄčé ąŠčéą┤ąĄą╗čīąĮąŠą╣ ą▒ąŠą╗čīčłąŠą╣ čüčéą░čéčīąĖ. ąōą╗ą░ą▓ąĮąŠąĄ - čŹč鹊 ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮąĄą╗čīąĘčÅ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ąĮąĖ KPI, ąĮąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĖ ąĮąĄą╗čīąĘčÅ ąĖąĘą╝ąĄąĮčÅčéčī ąŠčéąĮąŠčłąĄąĮąĖąĄ ą║ ą┐čĆąĖąŠčĆąĖč鹥čéčā. ą×ąĮ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ąĮą░čüą║ąŠą╗čīą║ąŠ čüąŠą▒čŗčéąĖąĄ ą▒čŗą╗ąŠ ąŠą┐ą░čüąĮčŗą╝ ą┤ą╗čÅ ą║ąŠą╝ą┐ą░ąĮąĖąĖ ąĖ ą║ą░ą║ ą║ąŠą╝ą┐ą░ąĮąĖčÅ čü ąĮąĖą╝ čüą┐čĆą░ą▓ąĖą╗ą░čüčī. ąØąŠ ą╝ąŠąČąĮąŠ ąĖąĘą╝ąĄąĮąĖčéčī ąŠčéąĮąŠčłąĄąĮąĖąĄ ą║ čĆąĄąĘčāą╗čīčéą░čéčā ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ čüąŠčéčĆčāą┤ąĮąĖą║ą░ ąĖą╗ąĖ ą┐ąŠą┤čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ. ą¤ąŠčüą║ąŠą╗čīą║čā ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠąĄ ą║ą░č湥čüčéą▓ąŠ čéčĆąĄą▒čāąĄčé ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓, ą╝čŗ ą╝ąŠąČąĄą╝ čüąŠąĘąĮą░č鹥ą╗čīąĮąŠ ąĖą┤čéąĖ ąĮą░ čĆą░ąĘąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī SLA ą┤ą╗čÅ ą┐ąŠą┤čĆą░ąĘą┤ąĄą╗ąĄąĮąĖą╣, ąĖą╝ąĄčÄčēąĖčģ čĆą░ąĘąĮčŗąĄ čĆąĄčüčāčĆčüąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ.
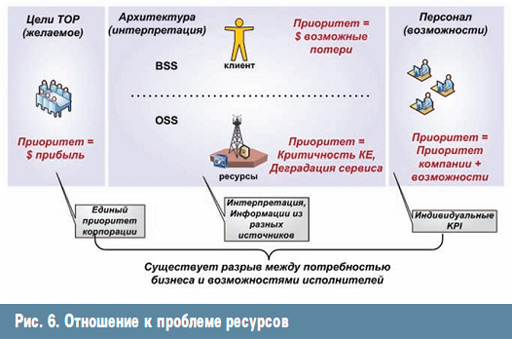
ą¤čĆąĖčüčéčāą┐ą░čÅ ą║ čüčéčĆąŠąĖč鹥ą╗čīčüčéą▓čā čüą║ą▓ąŠąĘąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĖ ąĄą┤ąĖąĮčŗčģ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓, ąĮą░ą┤ąŠ č湥čéą║ąŠ ą┐ąŠąĮąĖą╝ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓ą░ąČąĮčŗčģ ą╝ąŠą╝ąĄąĮč鹊ą▓.
ąĢą┤ąĖąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé - čŹč鹊 čåąĄą╗čī ą║ąŠčĆą┐ąŠčĆą░čåąĖąĖ ąĖ ą┐čĆąĄą┤ą╝ąĄčé ą┤ąŠą│ąŠą▓ąŠčĆąĄąĮąĮąŠčüčéąĖ, ą░ ą▓čĆąĄą╝čÅ čĆąĄą░ą║čåąĖąĖ ąĮą░ ąĖąĮčåąĖą┤ąĄąĮčéčŗ - čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖ ąČąĄą╗ą░ąĮąĖąĄ ą╗čÄą┤ąĄą╣. ąĢą┤ąĖąĮą░čÅ čłą║ą░ą╗ą░ - ą╗ąĖčłčī čüą┐ąŠčüąŠą▒ ąĘą░čäąĖą║čüąĖčĆąŠą▓ą░čéčī ąŠą▒čēąĖąĄ čåąĄąĮąĮąŠčüčéąĖ. ąĢą┤ąĖąĮą░čÅ čłą║ą░ą╗ą░ - čŹč鹊 čüą┐ąŠčüąŠą▒ ąŠčåąĄąĮą║ąĖ ą║ą░č湥čüčéą▓ą░ ą┐čĆąŠčåąĄčüčüą░ ąĖ ą▒ąĖąĘąĮąĄčü-čüąĖčüč鹥ą╝čŗ, ą░ ąĮąĄ ą║ą░č湥čüčéą▓ą░ ą╗čÄą┤ąĄą╣. ą¤ąŠčŹč鹊ą╝čā ąĄą┤ąĖąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé - ąĮąĄ ąĘąĮą░čćąĖčé ąĄą┤ąĖąĮčŗą╣ SLA. ąØąĄą╗čīąĘčÅ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ąĮą░ą┤ąŠ ą┤ąŠą│ąŠą▓ąŠčĆąĖčéčīčüčÅ ąŠ ą▓čĆąĄą╝ąĄąĮąĖ čĆąĄą░ą║čåąĖąĖ, ąĖąĮą░č湥 ą╗čÄą┤ąĖ ąĮą░čćąĖąĮą░čÄčé ą▒ąŠčĆąŠčéčīčüčÅ čü KPI, ąĘą░ą▒čŗą▓ą░čÅ ąŠą▒ ąĖąĮčåąĖą┤ąĄąĮč鹥. ąØąĄą╗čīąĘčÅ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ą▓ čüąĖčüč鹥ą╝ą░čģ ą░čüčéčĆąŠąĮąŠą╝ąĖč湥čüą║ąĖą╝ ą▓čĆąĄą╝ąĄąĮąĄą╝, ąĮą░ą┤ąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░čéčī ąŠčéč湥čéčŗ ąŠ čģąŠą┤ąĄ čĆąĄčłąĄąĮąĖčÅ ąĖąĮčåąĖą┤ąĄąĮč鹊ą▓.
ąÆąŠą┐čĆąŠčüčŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī čĆąĄčłąĄąĮąĖčÅ: "ąÆčüąĄ ą╗ąĖ ą║ą╗ąĖąĄąĮčéčŗ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ ą▓ą░ąČąĮčŗ ą┤ą╗čÅ ą▒ąĖąĘąĮąĄčüą░?", "ąÆčüąĄ ą╗ąĖ čüąŠą│ą╗ą░čüąĮčŗ čüąŠ čłą║ą░ą╗ąŠą╣ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓?", "ąśąĘą╝ąĄąĮąĖčéčī čĆąĄčüčāčĆčü ąĖą╗ąĖ ąĖąĘą╝ąĄąĮąĖčéčī SLA?".
ą×ą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ: -2011
ą¤ąŠčüąĄčēąĄąĮąĖą╣: 24285
ąĪčéą░čéčīąĖ ą┐ąŠ č鹥ą╝ąĄ
ąÉą▓č鹊čĆ
| |||
ąÆ čĆčāą▒čĆąĖą║čā "ąÜąŠą╝ą┐ą╗ąĄą║čüąĮčŗąĄ čĆąĄčłąĄąĮąĖčÅ. ąśąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣


